Comment enrichir le rapport liens externes de la Search Console avec Screaming Frog ?

Table des matières
La Search Console est vraiment un super outil.
Pourtant, certains rapports sont à mon sens peu exploités.
C'est le cas notamment de celui sur les liens externes (Liens > Exporter les liens externes > Liens les plus récents).
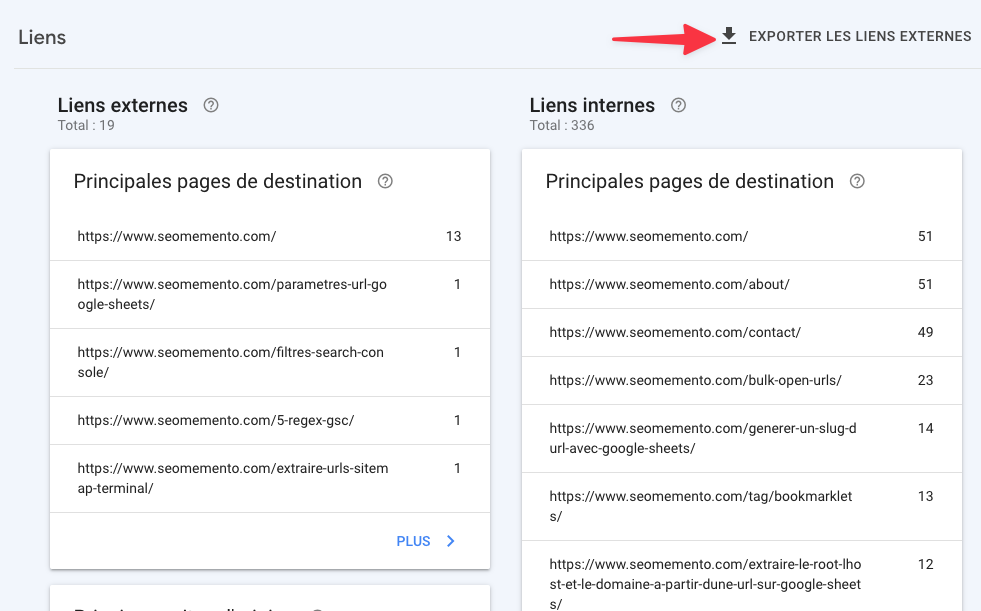
Alors, c'est vrai, il a plusieurs inconvénients :
- il est long à se mettre à jour
- il est incomplet (pour avoir plus de données, il faut éplucher les rapports "Principales pages de destination" et "Principaux sites d'origine")
- on y trouve souvent des référents bien spammy
Mais il est précieux parce qu'il donne une information capitale qu'on ne trouve nulle part ailleurs : la prise en compte du lien par Google.
Aujourd'hui, je te donne une petite astuce pour enrichir facilement ce rapport à l'aide de Screaming Frog.
Extraction personnalisée : présence, ancre et attribut "rel" du lien
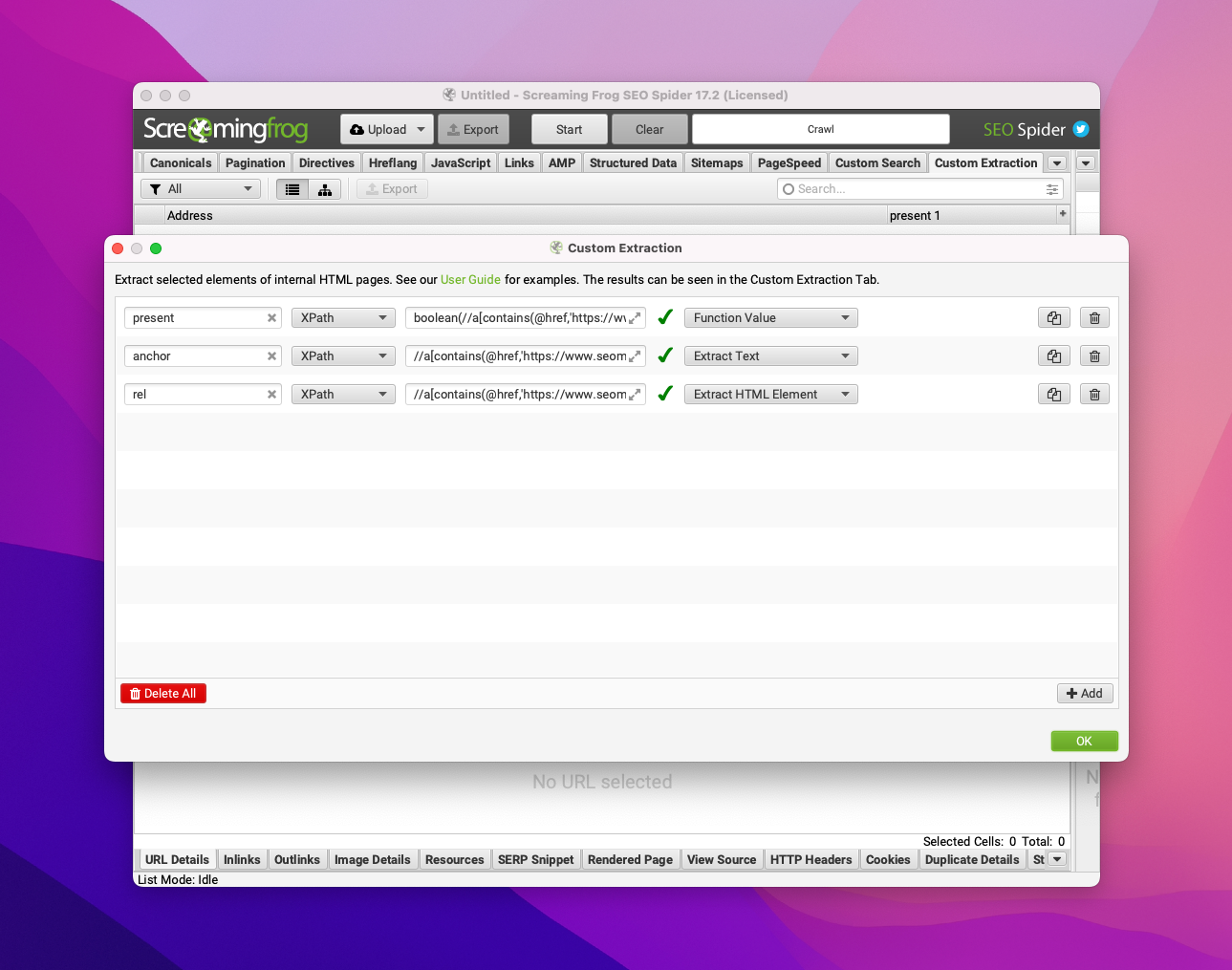
Pour donner du sens à l'export Search Console, je vais créer 3 extractions personnalisées (avec XPath) :
- un booléen indiquant si oui ou non le lien est présent dans la page
- l'ancre de ce lien
- l'attribut "rel" de ce lien
D'abord, je recherche dans la page un lien externe (ou plusieurs) contenant l'URL de mon site avec l'expression suivante :
//a[contains(@href,'https://www.seomemento.com')]Puis je construis chaque XPath à partir de cette expression.
Voici ce que ça donne :
boolean(//a[contains(@href,'https://www.seomemento.com')])Le lien est-il présent ?
//a[contains(@href,'https://www.seomemento.com')]/text()Quelle est l'ancre du lien ?
//a[contains(@href,'https://www.seomemento.com')]/@relQuel est l'attribut "rel" du lien ?
Crawl et analyse
Il ne reste plus qu'à lancer Screaming Frog en mode liste, en prenant bien soin de configurer les extractions personnalisées et de choisir Googlebot en User-Agent.
Une fois le crawl terminé, tu auras à la fois :
- des informations sur la page qui te fait un backlink :
- répond-elle en 200 ?
- est-elle crawlable ?
- est-elle indexable ? (noindex, canonical)
- des informations sur le backlink :
- est-il présent dans la page ?
- quelle est son ancre ?
- est-il en nofollow ?
Bien entendu, si la page te fait plusieurs backlinks, tu auras autant de colonnes que de liens, comme c'est le cas dans mon exemple.
Si tu ne souhaites récupérer que le premier lien trouvé, il faudra donc adapter un peu les expressions XPath :
- pour l'ancre du 1er lien trouvé :
(//a[contains(@href,'https://www.seomemento.com')]/text())[1] - pour l'attribut rel du 1er lien trouvé :
(//a[contains(@href,'https://www.seomemento.com')]/text())[1]
Et voilà !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.