
Extraire les URLs d'un sitemap XML en une ligne de commande

Table des matières
Aujourd'hui, petite astuce qui fait suite à ce tweet de @bunbeau qui a attiré mon attention la semaine dernière.
D'ailleurs pour celles et ceux qui veulent gagner du temps :
— Bunbeau / Wolfy (@bunbeau) June 22, 2022
1. Vous balancez votre sitemap là-dedans : https://t.co/t4tN0m6h8r
2. Copy/Past dans un projet (neuf ou non) sur @indexmenow
3. Faites vous un thé ou un café (ou un matcha)#SEO #Indexation https://t.co/JmbgibaxY4
Dans ce tweet, Pascal cite SEOwl, une solution de monitoring SEO qui propose, entre autres, un outil gratuit pour extraire les URLs d'un sitemap XML.
Dans les réponses à son tweet, plusieurs consultants SEO ont proposé des alternatives à SEOwl comme Screaming Frog, ou encore Google Sheets.
Le problème avec Screaming Frog, comme l'a relevé Pascal, c'est que son interface graphique est assez lourde et qu'il met donc beaucoup de temps à se lancer.
C'est juste affreusement long d'ouvrir SF à mon goût :D
— Bunbeau / Wolfy (@bunbeau) June 22, 2022
Pour ce type d'opérations (parsing de fichier XML), clairement, la grenouille n'est pas la meilleure option.
Je suis donc parti en quête d'une solution plus rapide en ligne de commande.
Ready ? Let's go !
1ère étape : télécharger le sitemap XML
Pour télécharger le sitemap, je vais tout simplement utiliser la commande curl avec l'option -s (silent) suivie de l'URL du fichier.
curl -s https://www.seomemento.com/sitemap-posts.xml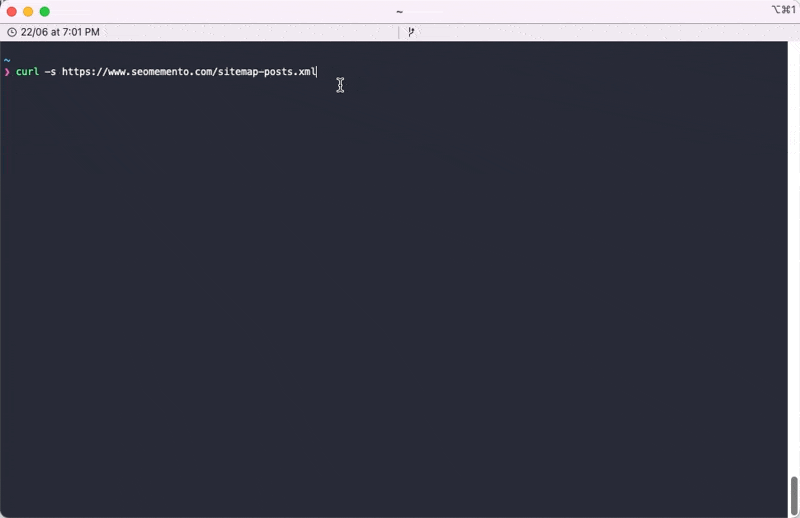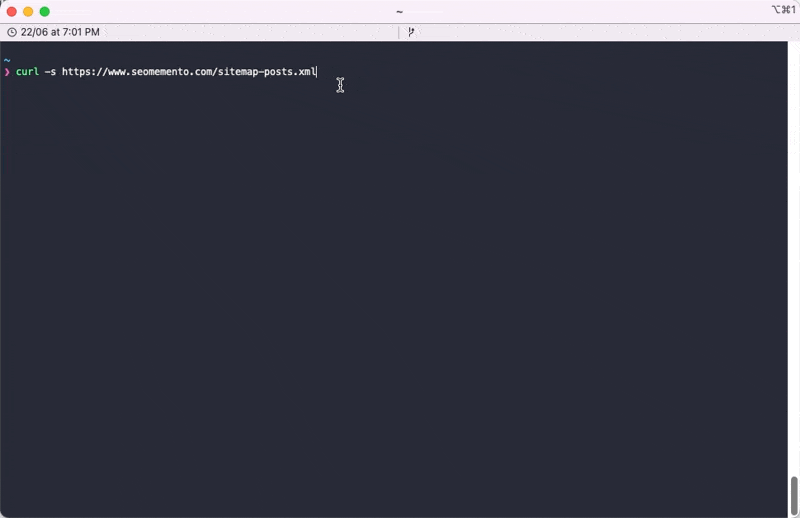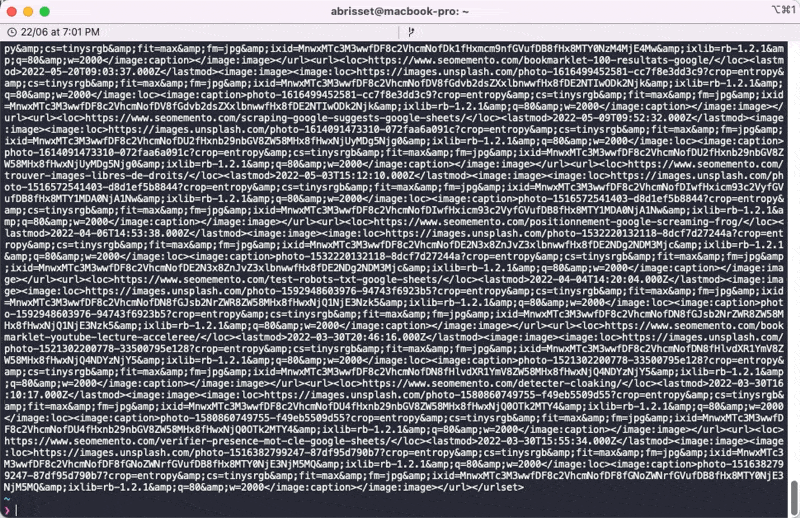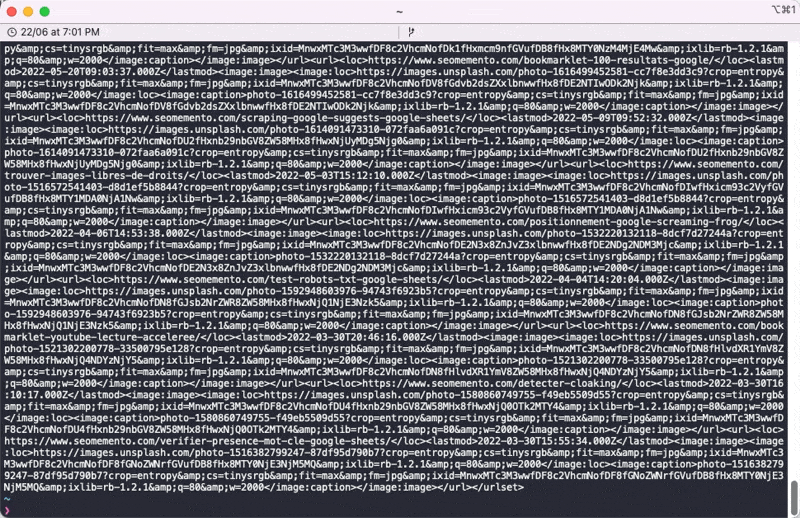
Si tu es sur Mac, comme moi, il me semble que curl est installé par défaut. Pour t'en assurer, tu peux exécuter la commande curl -v.
Je vais ensuite "passer" le résultat de la commande curl à un autre programme en utilisant le | (pipe).
2ème étape : extraire les URLs
Ce programme, c'est xmllint.
Il s'agit d'un utilitaire bien pratique qui permet de parser des fichiers XML et d'en extraire des données à l'aide d'expressions XPath.
Là aussi, je crois qu'il est installé par défaut sur Mac OS (sinon, Homebrew est ton ami).
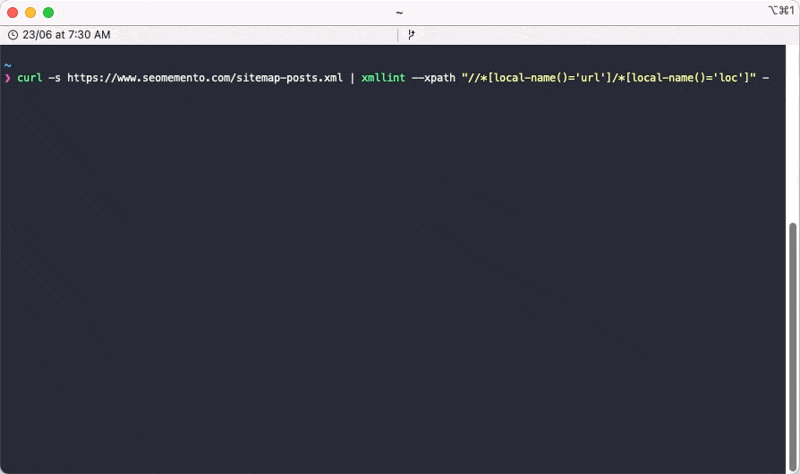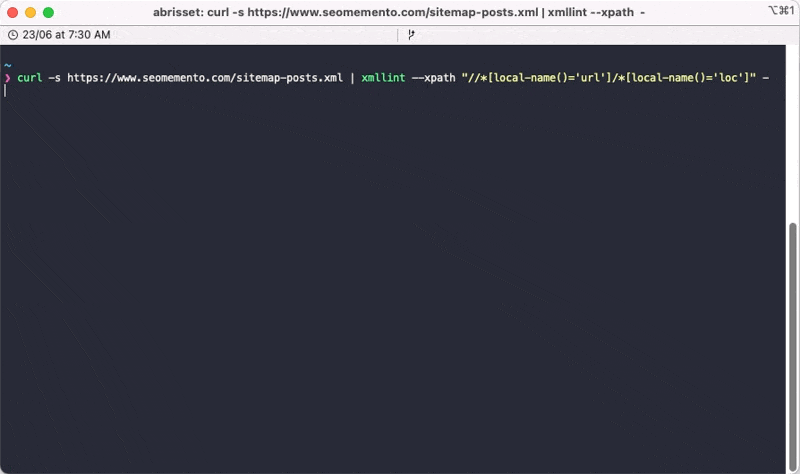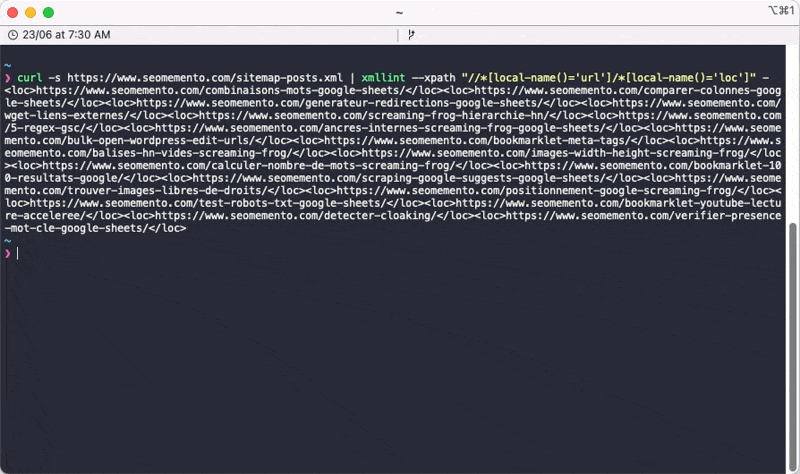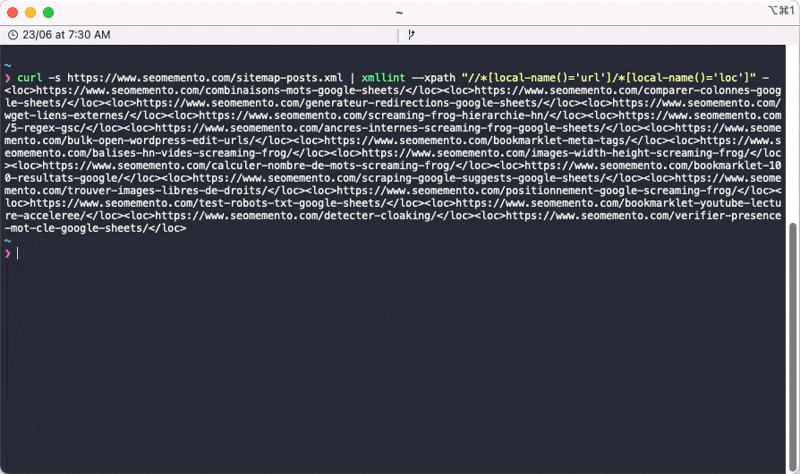
La requête XPath à utiliser est la suivante : //*[local-name()='url']/*[local-name()='loc'].
Tu te demandes sûrement pourquoi j'ai utilisé la fonction local-name() plutôt qu'un simple //loc, non ?
En fait, c'est parce que le namespace du protocole sitemap (sitemaps.org) – xmlns="http://www.sitemaps.org/schemas/sitemap/0.9" – est un namespace par défaut, sans préfixe.
Pour faire court, cela signifie que si j'utilise l'expression XPath //loc, le résultat sera vide car XPath, dans sa version 1.0, va retourner l'ensemble des élements <loc> qui n'ont pas été déclarés dans un namespace. Autrement dit, aucun.
Pour contourner le problème, j'utilise donc la fonction local-name() : elle permet de retourner la partie locale d'un noeud, sans son préfixe. En l'occurrence, ici, je cherche les noeuds dont la partie locale du nom est "url" puis "loc".
Bon, je m'écarte un peu du sujet du jour, mais si cette histoire de namespace t'intéresse, tu trouveras plus d'infos ici et là.
Revenons-en à xmllint.
La commande à exécuter dans le terminal est donc la suivante :
xmllint --xpath "//*[local-name()='url']/*[local-name()='loc']" -Note bien ici la présence du tiret à la fin, qui indique à xmllint qu'il doit lire le contenu de l'entrée standard (stdin), c'est-à-dire le résultat de la commande curl précédente.
3ème étape : nettoyer le code XML
Il ne me reste plus qu'à nettoyer le code en supprimant les occurrences de <loc> et en séparant chaque URL par un retour à la ligne.
Ce que je vais faire en utilisant la commande sed.
D'abord, je supprime toutes les occurrences de <loc> avec sed 's/<loc>//g'.
Explications :
- j'indique à sed d'opérer une substitution avec
s - je lui donne la chaîne à trouver :
<loc> - je lui donne la chaîne de substitution, en l'occurrence ici une chaîne vide
- je précise que la commande est globale avec
g(toutes les occurrences trouvées doivent être remplacées)
Ensuite, je remplace chaque occurrence de </loc> par un retour à la ligne (\n) avec sed 's/<\/loc>/\n/g'. Attention ici à bien échapper le slash.
Pour combiner les deux commandes, je les sépare par un point-virgule.
Ce qui donne : sed 's/<loc>//g; s/<\/loc>/\n/g'.
La commande finale
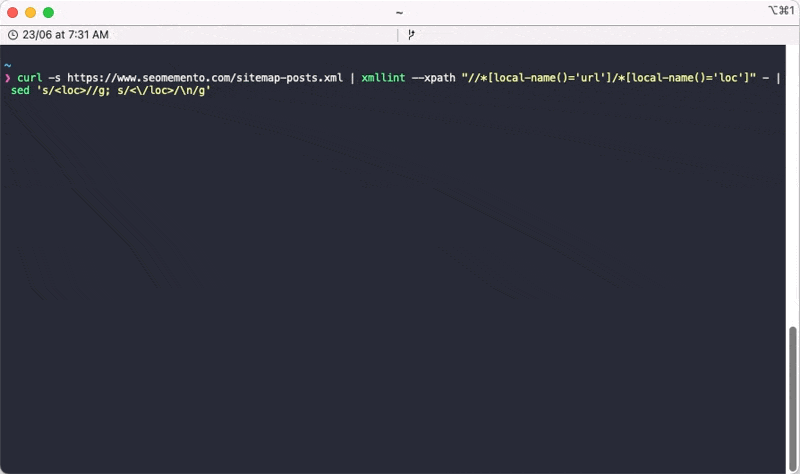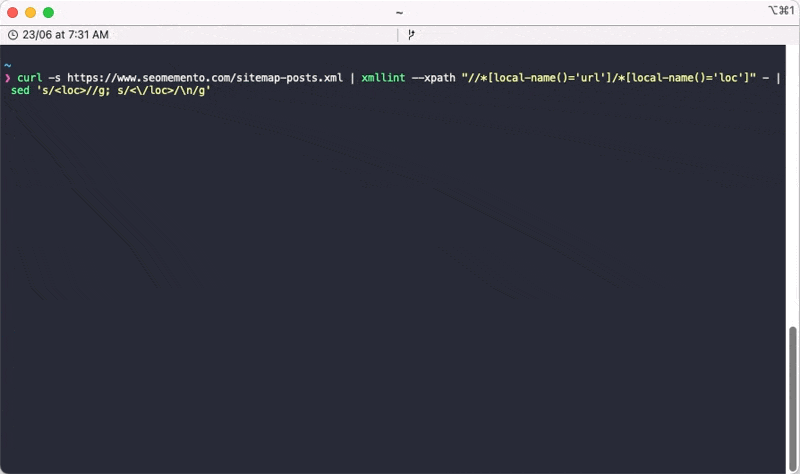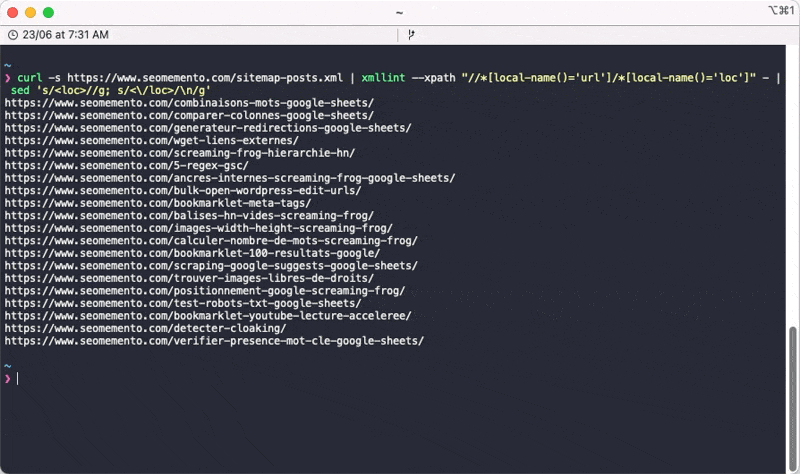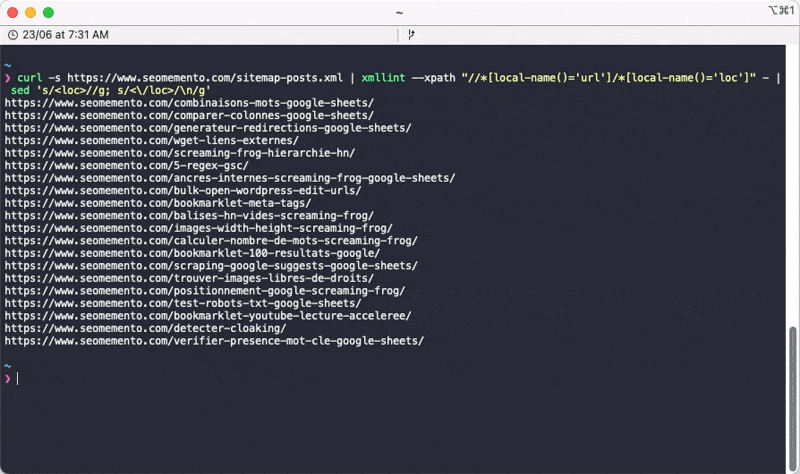
Et voilà le résultat.
curl -s https://www.seomemento.com/sitemap-posts.xml | xmllint --xpath "//*[local-name()='url']/*[local-name()='loc']" - | sed 's/<loc>//g; s/<\/loc>/\n/g'Il faut bien entendu que tu remplaces https://www.seomemento.com/sitemap-posts.xml par l'URL de ton sitemap.
Bonus
Si tu veux enregistrer les URLs dans un fichier plutôt que de les afficher dans le terminal, ajoute simplement > urls.txt à la fin de ta commande.
Si tu souhaites simplement les copier dans ton presse-papier, ajoute plutôt | pbcopy.
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.


