
Comment scraper proprement avec IMPORTXML ?
Table des matières
Quand on utilise IMPORTXML pour extraire le contenu de plusieurs balises (exemple : toutes les balises h2 d'une page), les différentes valeurs trouvées s'affichent par défaut les unes en dessous des autres, sur plusieurs lignes.
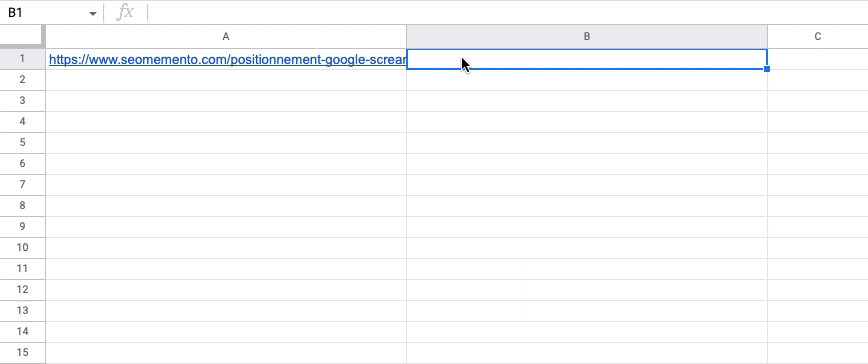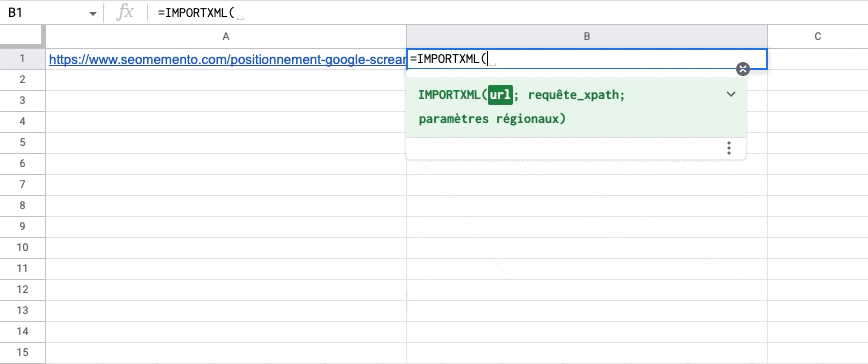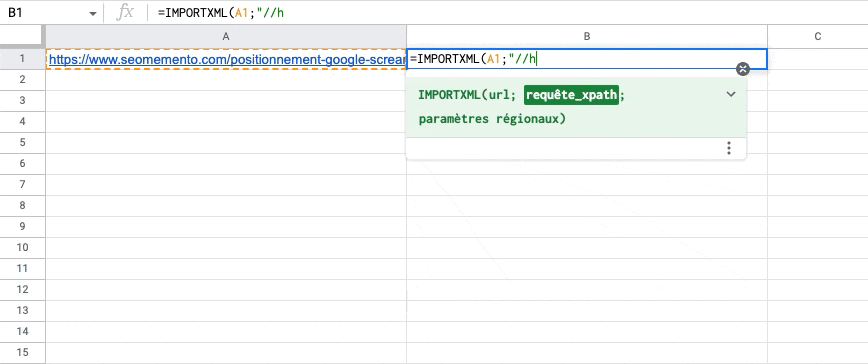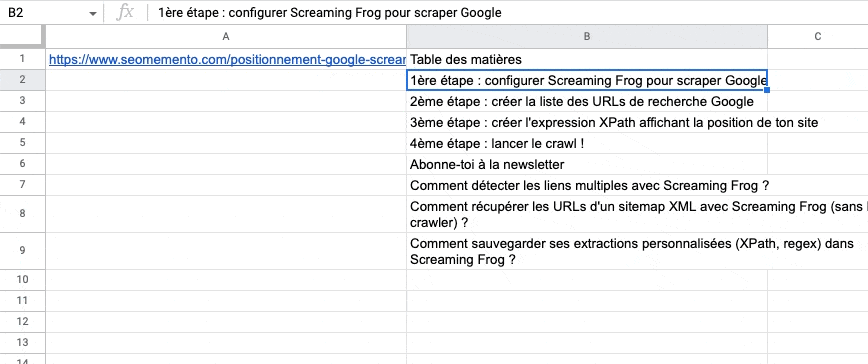
C'est embêtant.
Pourquoi ?
Parce que si on ajoute d'autres URLs, on ne peut pas "tirer" la formule vers le bas avec la poignée de recopie.
Cela déclenche en effet une erreur #REF! (message d'erreur : Le résultat n'a pas été développé, pour ne pas écraser les données de X).

Une solution peut être d'utiliser la fonction TEXTJOIN avec comme délimiteur le retour à la ligne, CHAR(10).
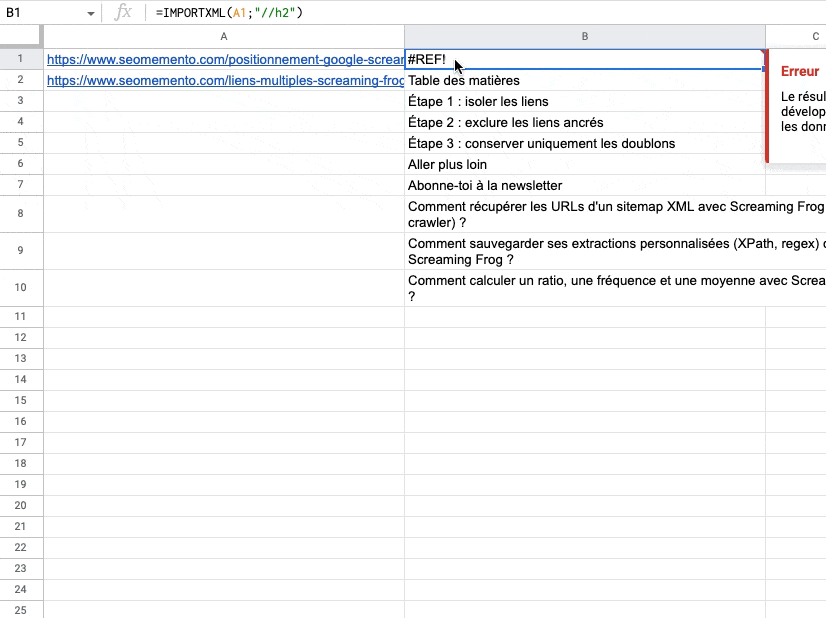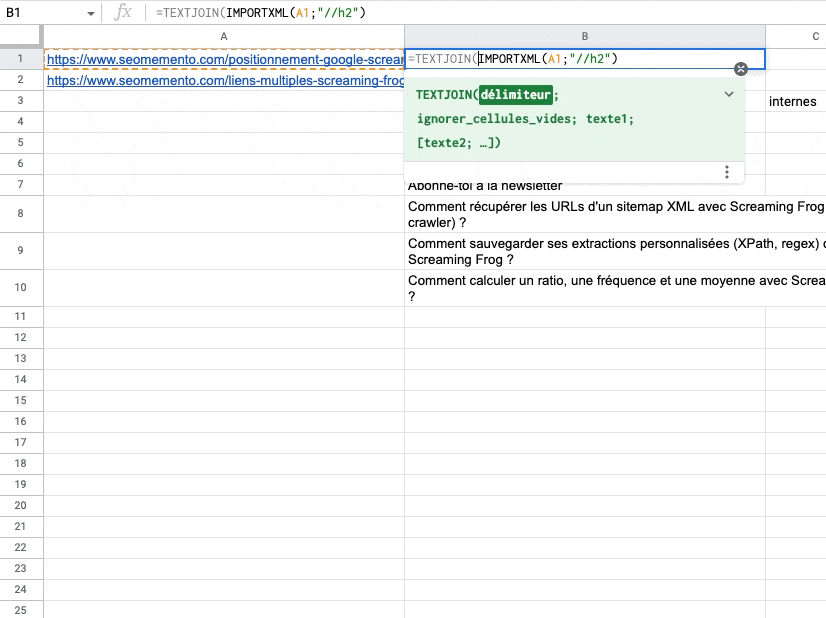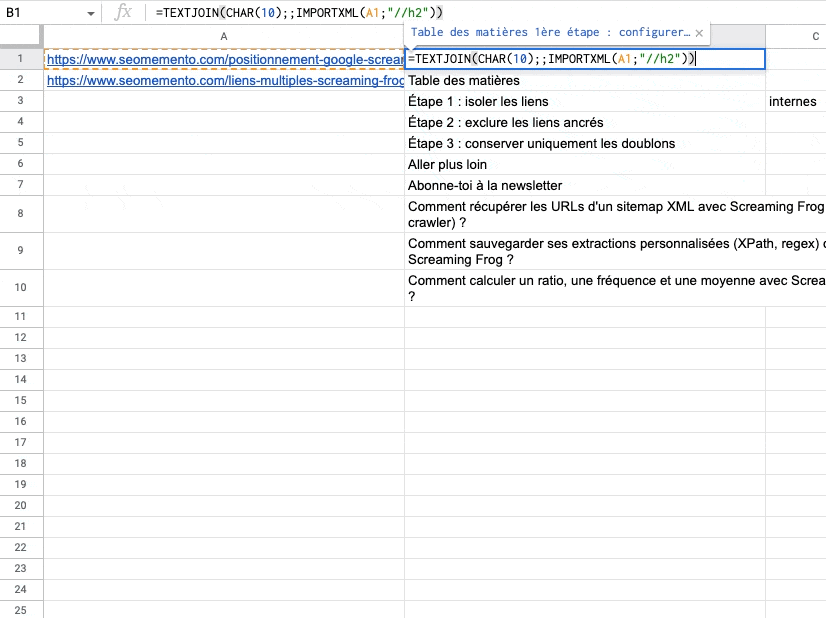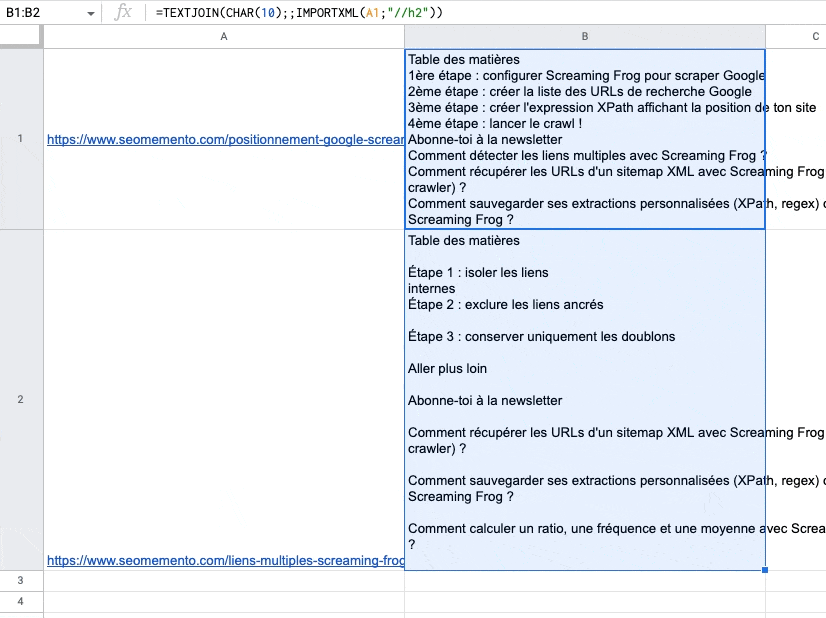
Problème : si les balises extraites contiennent un ou plusieurs nœuds "enfants" (par exemple des balises strong à l'intérieur de balises h2), alors ces nœuds enfants se retrouvent dans plusieurs colonnes.
Ils seront donc "séparés" par un retour à la ligne avec TEXTJOIN.
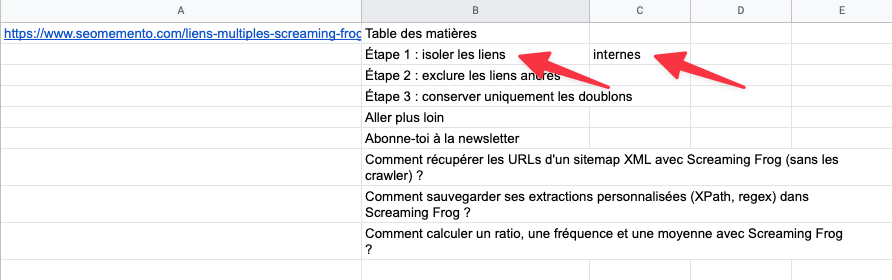
C'est le cas ici avec "isoler les liens" et "internes" car "internes" est dans une balise strong, elle-même à l'intérieur d'une balise h2.
La solution ? Utiliser les fonctions d'assistance LAMBDA.
Ici, je vais m'aider de la fonction BYROW, dont j'ai déjà parlé dans une précédente newsletter.
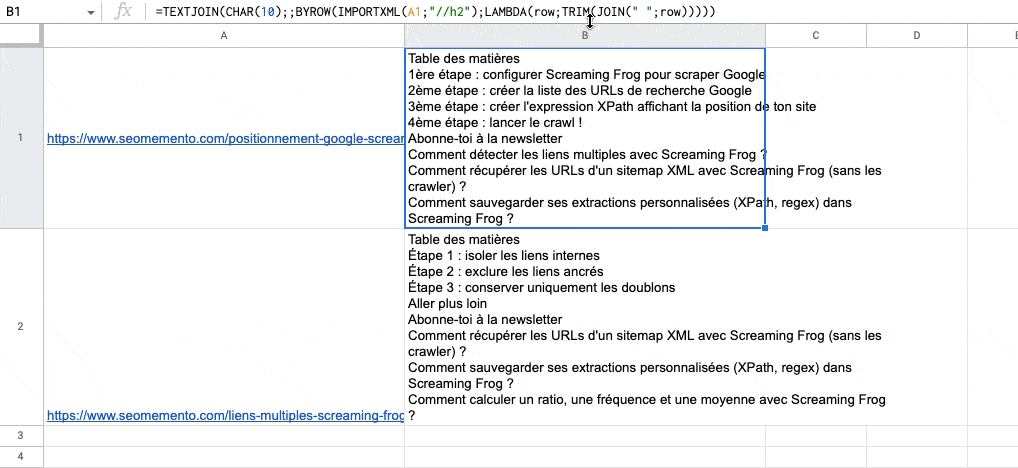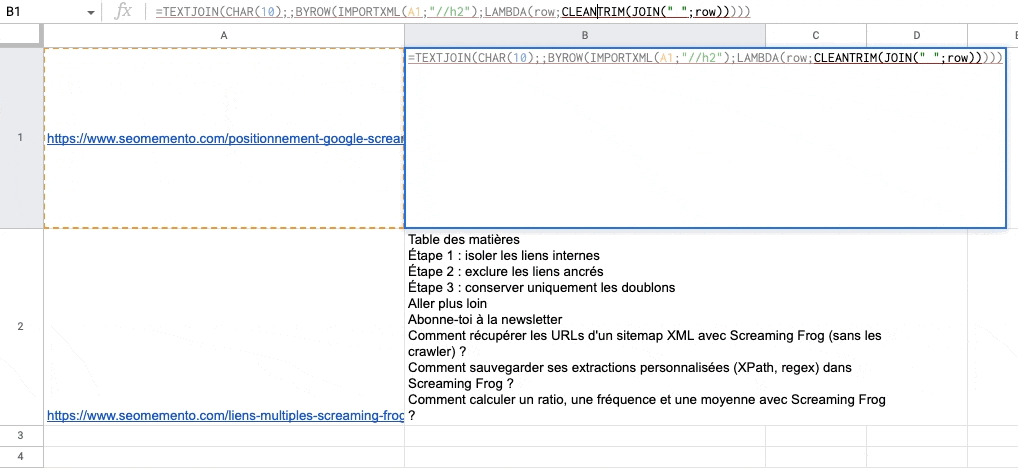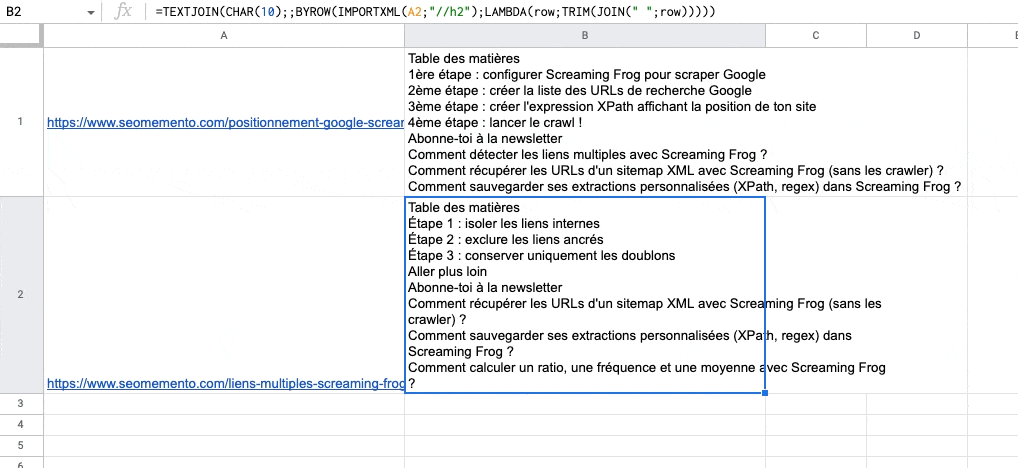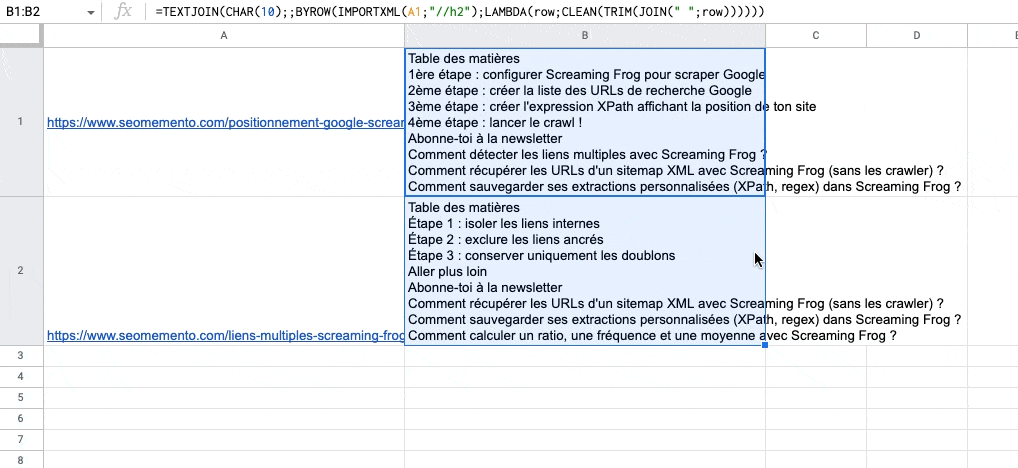
L'objectif : concaténer les données renvoyées par IMPORTXML lorsque celles-ci se déploient sur plusieurs colonnes.
=BYROW(IMPORTXML(A1;"//h2");LAMBDA(row;TRIM(JOIN(" ";row))))Traduction : pour chaque ligne (row) de données renvoyées par IMPORTXML, concatène-moi chacune des valeurs (JOIN) en supprimant les espaces superflus (TRIM).
BYROW
C'est mieux mais ce n'est pas parfait. Il reste des retours à la ligne récalcitrants.
On va donc ajouter CLEAN pour les supprimer.
Dernière étape. Ajouter un IFERROR devant le tout pour gérer les cas où IMPORTXML renverrait un contenu vide ou une erreur.

Et voilà la formule finale !
=IFERROR(TEXTJOIN(CHAR(10);;BYROW(IMPORTXML(A1;"//h2");LAMBDA(row;CLEAN(TRIM(JOIN(" ";row))))));"no results")- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.



{kind=link}