Comment identifier des mentions sans lien avec Screaming Frog ?

Table des matières
Aujourd'hui, j'aimerais te partager une petite astuce pour identifier facilement les mentions sans lien avec Screaming Frog.
La recherche de ces "unbranded brand mentions" figure parmi les premiers quick wins à aller chercher en matière de netlinking.
C'est plutôt adapté aux sites ayant déjà une certaine notoriété, c'est vrai, mais on trouve aussi parfois quelques pépites sur des sites plus modestes.
Concrètement, il y a deux façons de faire :
- soit tu ouvres chaque page où tu as trouvé une mention et tu vérifies à la main si le lien est présent dans le code source
- soit tu automatises le processus avec Screaming Frog
Je te montre ici la deuxième option 😉
Étape 1 : scraper les résultats
La 1ère étape consiste à récupérer les URLs des pages :
- qui ne sont pas issues de mon site
- qui citent l'URL de mon site
Rien de bien compliqué.
Je tape la commande Google suivante :
"seomemento.com" -site:seomemento.comPuis je passe en mode 100 résultats par page, avec l'extension Centuple par exemple.
Et enfin je scrape les URLs des résultats organiques, en utilisant Blue Links par exemple.
Étape 2 : construire la requête XPath
Maintenant que j'ai les URLs, je vais essayer de trouver l'expression XPath qui répond à mon besoin, à savoir :
- vérifier si le nom de domaine (ici "seomemento.com") est mentionné dans le body de la page
- vérifier s'il y a un lien a href pointant vers une URL de ce site
Recherche de la mention
Pour vérifier si le texte "seomemento.com" figure dans le body, j'utilise l'expression suivante :
boolean(//text()[not(parent::script or parent::noscript or parent::style)][contains(., "seomemento.com")])Explications :
- je recherche les noeuds textes avec
text() - je "supprime" les éléments textuels qui sont à l'intérieur de balises
script,noscriptoustyleavec[not(parent::script or parent::noscript or parent::style) - je sélectionne ceux qui contiennent "seomemento.com" avec
[contains(., "seomemento.com")]) - et j'entoure le tout de la fonction
boolean: si au moins un élément est trouvé, la fonction renverratrue, sinon elle renverrafalse
Recherche du lien
Pour vérifier si un lien externe existe vers mon site, j'utilise l'expression suivante :
boolean(//a[contains(@href, 'seomemento.com')])Explications :
- je cherche parmi les liens de la page (
//a) - ... ceux qui ont un attribut href contenant "seomemento.com" (
[contains(@href, 'seomemento.com')]) - et j'entoure le tout de la fonction
boolean: si au moins un élément est trouvé, la fonction renverratrue, sinon elle renverrafalse
Expression finale
Il ne me reste plus qu'à regrouper les deux expressions.
Et oui rappelle-toi, pour identifier les pages intéressantes, il faut satisfaire les deux conditions suivantes :
- la mention doit être présente (a priori c'est le cas avec la commande Google qu'on a utilisée)
- le lien doit être absent
Je regroupe donc les deux expressions avec and et j'ajoute not devant de façon à relever uniquement les pages qui ne remplissent pas les deux critères.
Enfin, je préfixe le tout de la fonction boolean.
Ce qui donne :
boolean(not(//text()[not(parent::script or parent::noscript or parent::style)][contains(., "seomemento.com")] and //a[contains(@href, 'seomemento.com')]))Si le résultat de cette fonction est true, on est probablement en présence d'une mention sans lien.
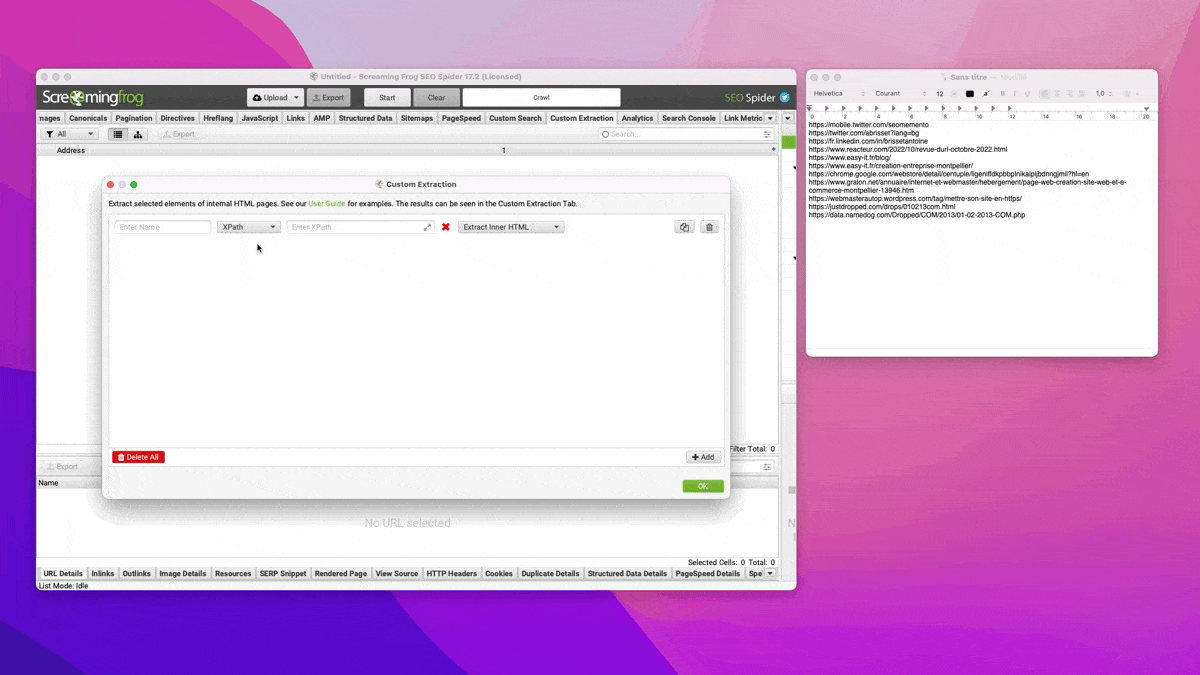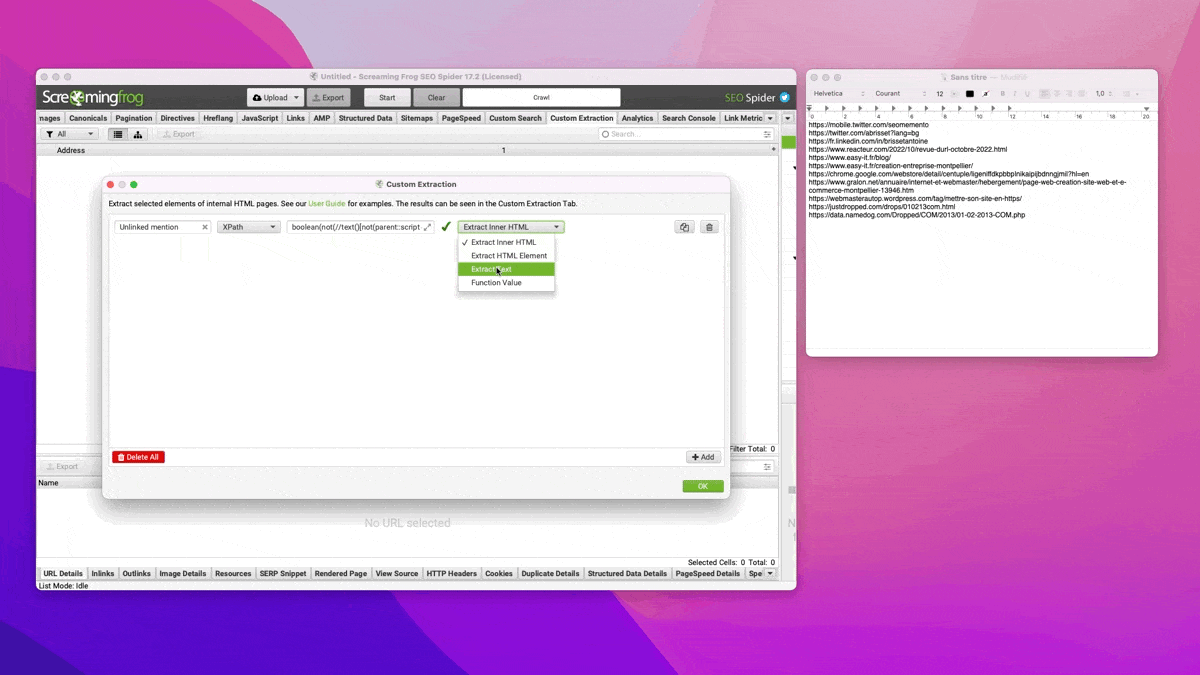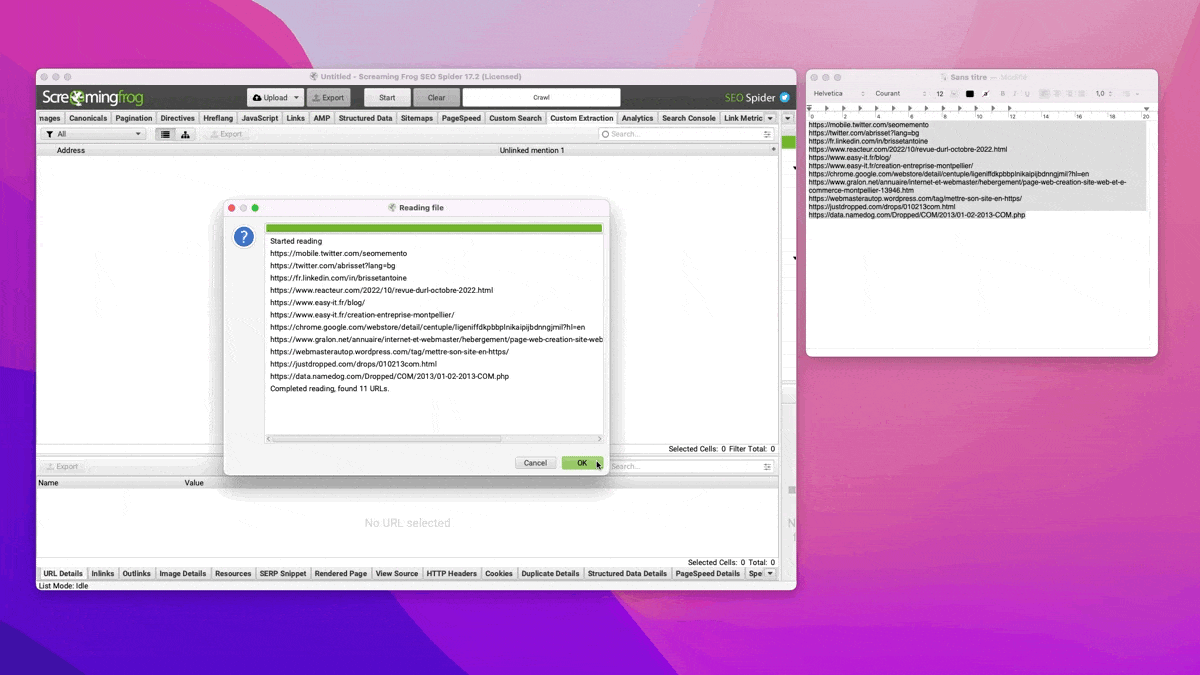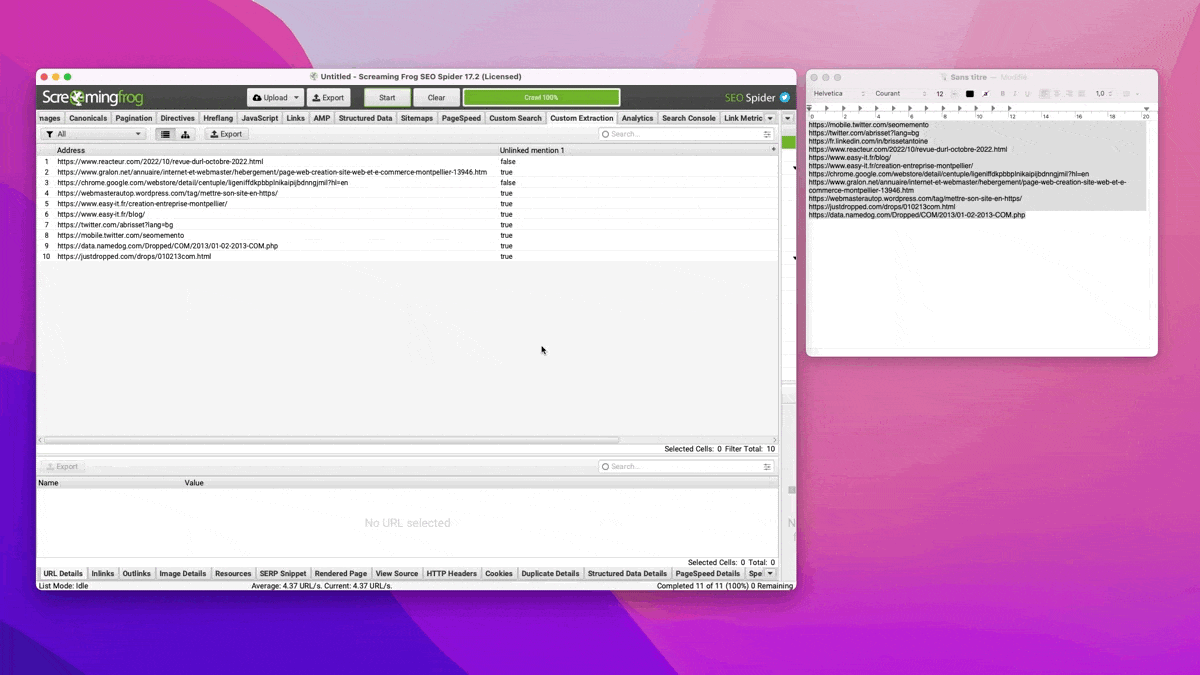
Étape 3 : lancer Screaming Frog
Là c'est assez simple : j'ouvre Screaming Frog, je crée une extraction personnalisée et je crawle les URLs collectées à l'étape 1 en mode liste.
Limites
Je vois 2 limites à cette méthode :
- si le contenu de la page a changé depuis la dernière mise en cache de Google
- s'il existe un lien sur la page mais que celui-ci est un lien raccourci type bit.ly
Dans les 2 cas, l'extraction retournera un faux positif dans Screaming Frog.
Instant promo : j'ai ajouté un nouvel outil dans le template Gadgeto qui permet de rechercher automatiquement des mentions sans lien à partir d'une liste d'URLs.
Il donne les infos suivantes :
- présence ou non d'une mention
- présence ou non d'un lien
- ancre du lien
- URL cible du lien
- attribut rel du lien
Voilà à quoi ça ressemble.
Si tu veux en savoir plus sur Gadgeto, c'est par ici : https://www.gadgeto.app
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.