Comment extraire les images sans attributs width et height avec Screaming Frog ?

Table des matières
Aujourd'hui, je vais te partager une petite astuce qui, je l'espère, te fera gagner du temps lors de tes audits webperf.
En matière de vitesse de chargement, l'optimisation des images est souvent un des premiers chantiers à mettre en place : compression, lazyloading, images adaptatives (en fonction de la taille d'écran du visiteur), etc.
Un élément important à contrôler également est le setting des attributs width et height.
En effet, si la largeur (width) ou la hauteur (height) d'une image n'est pas définie, alors le navigateur n'a aucune idée de l'espace qu'il doit allouer à cet élément lors du chargement de la page, ce qui peut dégrader le CLS (Cumulative Layout Shift), l'un des 3 indicateurs des Core Web Vitals.
Cela fait d'ailleurs partie des points de contrôle de l'outil Lighthouse.

OK. Du coup, comment faire pour extraire, sur un site, l'ensemble des images qui n'ont pas d'attributs width et/ou height définis ?
Et bien, comme tu l'as deviné à la lecture du titre, en utilisant Screaming Frog !
Si tu es familier de l'outil, tu vas sûrement me dire : euh... ouais facile, suffit de brancher Screaming Frog à l'API PageSpeed Insights et le tour est joué !
Alors oui... mais non.
Oui, il est possible d'obtenir ce résultat en connectant Screaming Frog à l'API PageSpeed Insights. Une fois le crawl terminé, le rapport sera disponible dans PageSpeed > Image Elements Do Not Have Explicit Width & Height.
Problème : c'est (beaucoup) trop lent.
En effet, il faut attendre la récupération des résultats de l'API pour chaque URL crawlée. Sur des milliers d'URLs, cela représente un coût non négligeable.
Bref, si tu as besoin d'une analyse rapide, ce n'est clairement pas adapté.
Pour aller plus vite, il faudrait plutôt être en mesure de récupérer les résultats lors du crawl, en une seule passe.
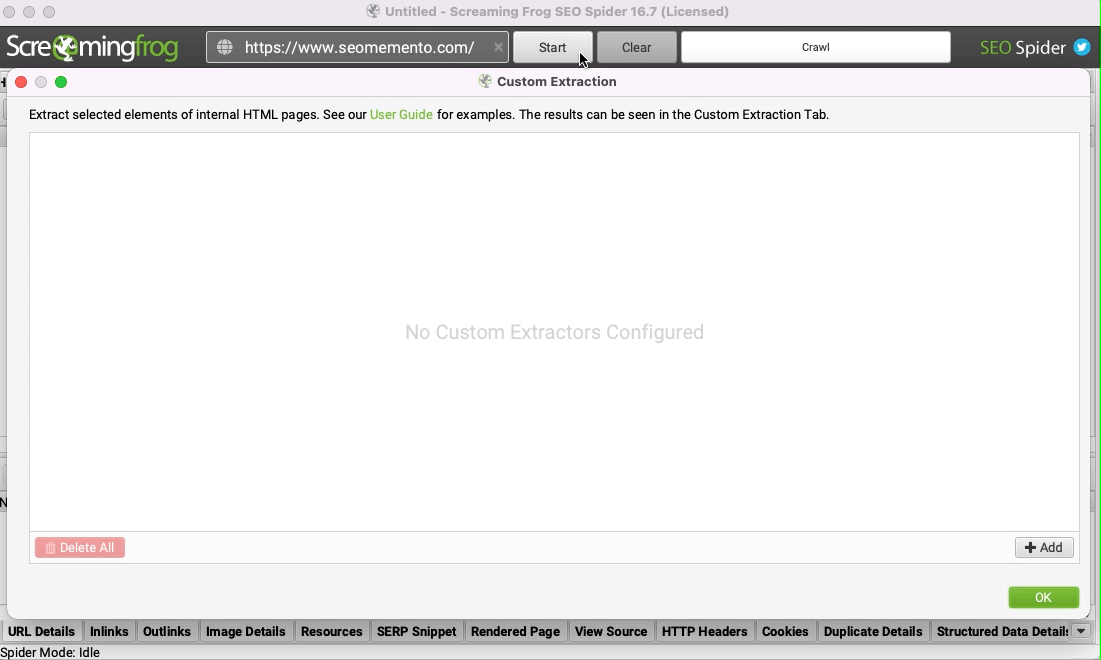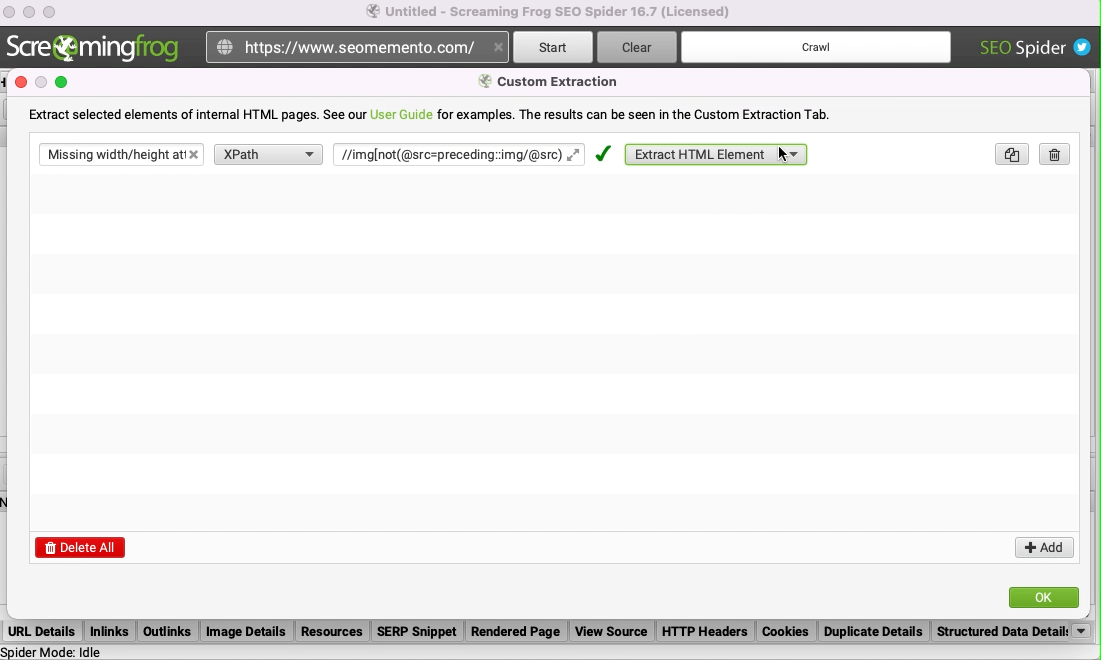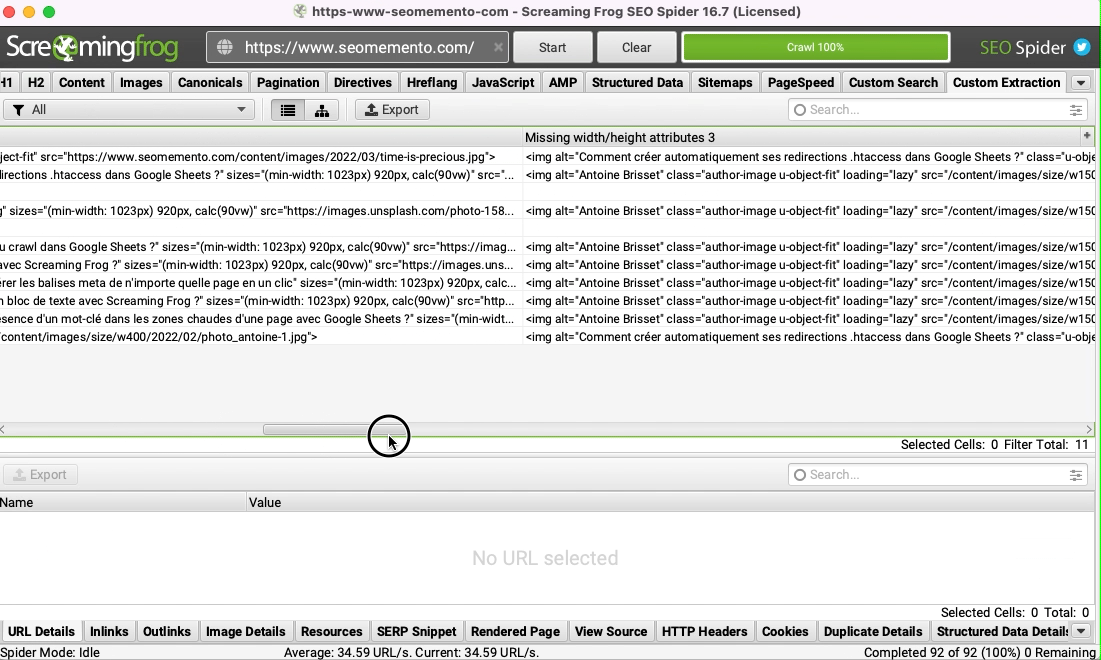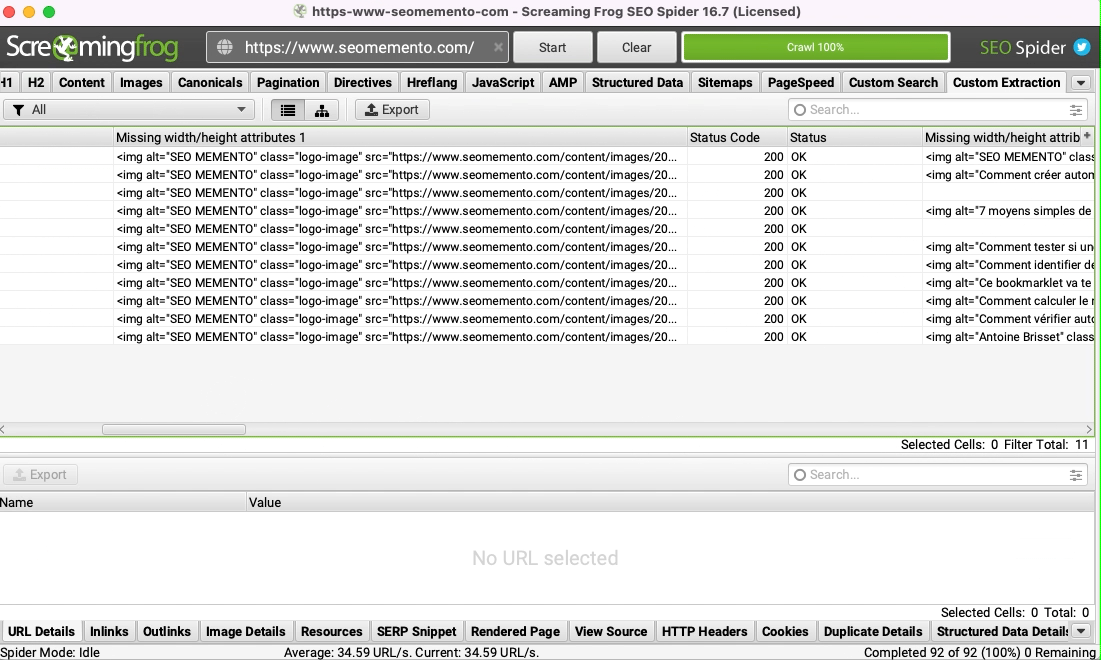
On va donc faire différemment et utiliser la fonctionnalité "Custom Extraction", par le biais d'une requête XPath.
La voici :
//img[not(@src=preceding::img/@src) and (not(@width) or not(@height))]L'idée ici, c'est de trouver toutes les images concernées par le problème d'attribut(s) manquant(s), en prenant soin de les dédoublonner.
Explications :
//img: je cherche dans la page toutes les imagesnot(@src=preceding::img/@src): dont l'attribut src n'est pas égal à celui d'une image déjà rencontrée dans un noeud précédent (c'est ici que je filtre les doublons)and (not(@width) or not(@height)): et, c'est le principal, qui n'ont pas d'attribut width ou d'attribut height
Dans Screaming Frog, rends-toi dans le menu Configuration > Custom > Extraction.
Clique sur Add.
Donne un nom à ton extraction (exemple Missing width/height attributes).
Sélectionne "XPath" puis colle la requête affichée plus haut.
Choisis "Extract HTML element" puis valide.
Une fois le crawl lancé, les balises <img> sans largeur ou sans hauteur s'afficheront dans l'onglet "Custom Extraction".
Et voilà !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.