
Comment vérifier ses liens d'affiliation avec Screaming Frog ?
Table des matières
Quand on fait de l'édition de sites, on passe beaucoup de temps à créer du contenu, à le promouvoir, à faire des liens.
Mais on oublie parfois le plus important : s'assurer que les liens d'affiliation qu'on a glissés dans nos contenus sont valides.
Autrement dit :
- qu'ils contiennent bien l'ID affilié
- qu'ils répondent bien en 200
Aujourd'hui, je te propose donc une méthode très basique pour vérifier tes liens d'affiliation avec Screaming Frog.
Pré-requis
Avant de lancer le crawl, assure-toi tout d'abord :
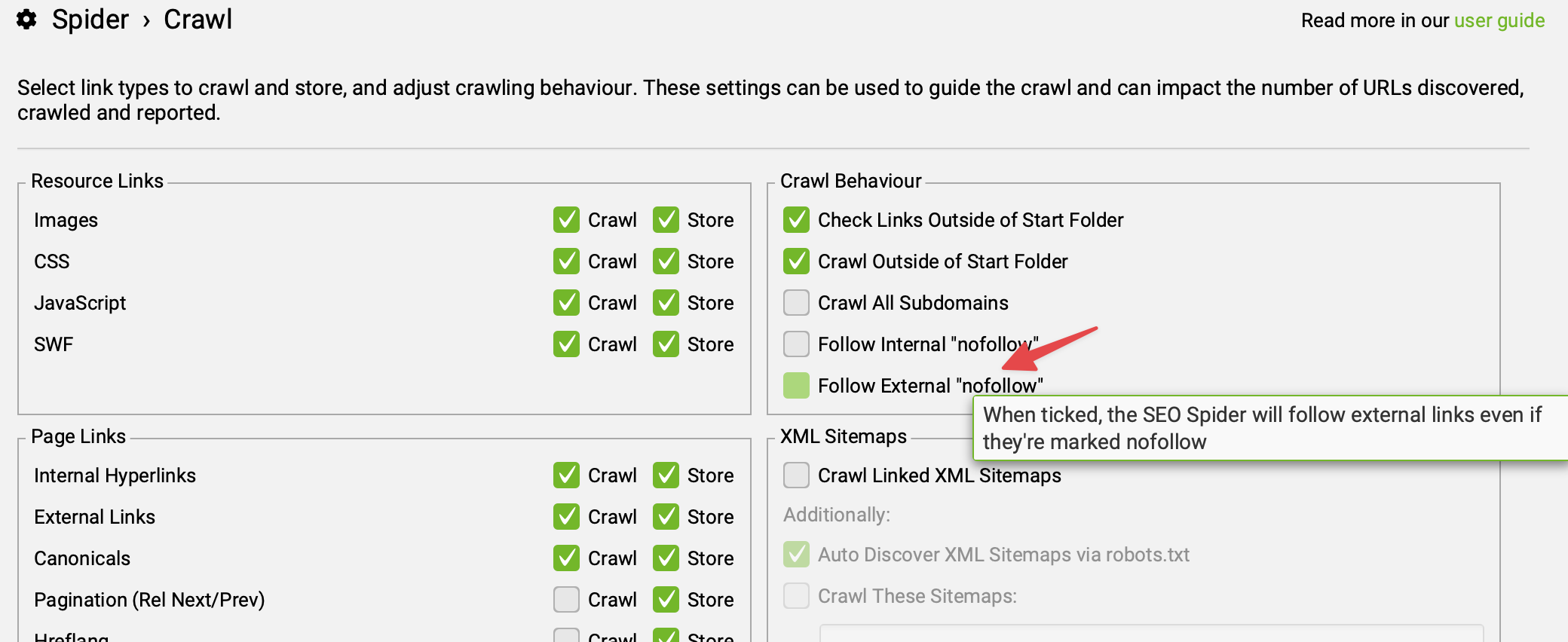
- que tu autorises bien Screaming Frog à suivre les liens externes en nofollow, au cas où tu as ajouté du nofollow sur tes liens d'affiliation
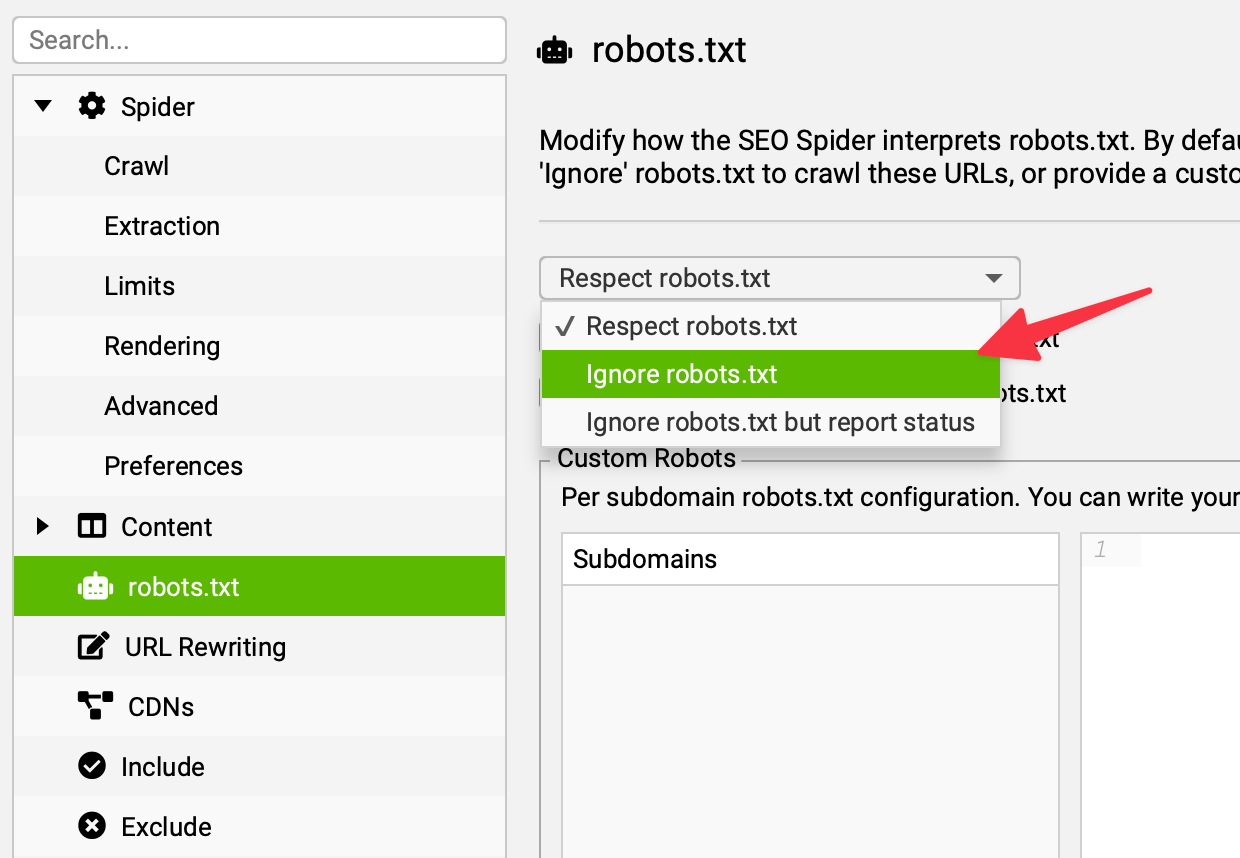
- que tu autorises bien Screaming Frog à ignorer les directives du robots.txt, au cas où tu utilises des liens vers des redirections d'URLs bloquées au crawl (exemple : liens de type
monsite.com/go/monaffiliationet directiveDisallow: /go/dans le robots.txt)
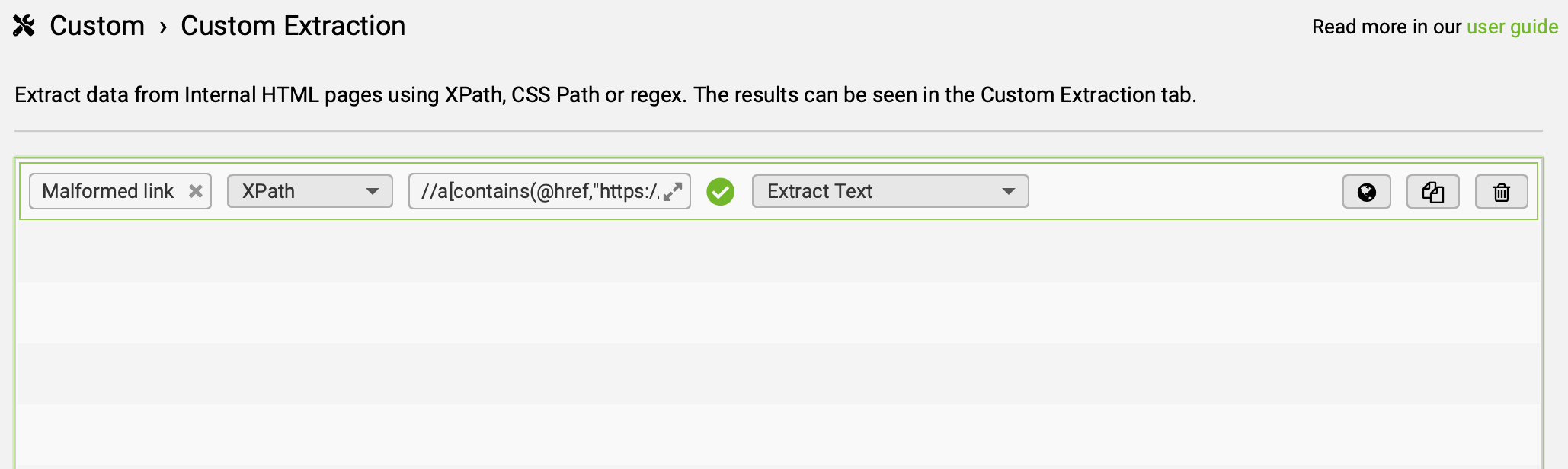
1ère étape : créer une custom extraction
L'idée ici, c'est d'extraire les liens de la page contenant l'URL du site affilié mais ne contenant pas d'ID de tracking, ce qui équivaut à une perte sèche de revenus (ça m'est déjà arrivé... plusieurs fois).
Exemple, pour Amazon, ça donnerait :
//a[contains(@href,"https://www.amazon.fr/") and not(contains(@href, "tag="))]//@hrefExtraction des liens vers amazon.fr ne contenant pas le param ?tag
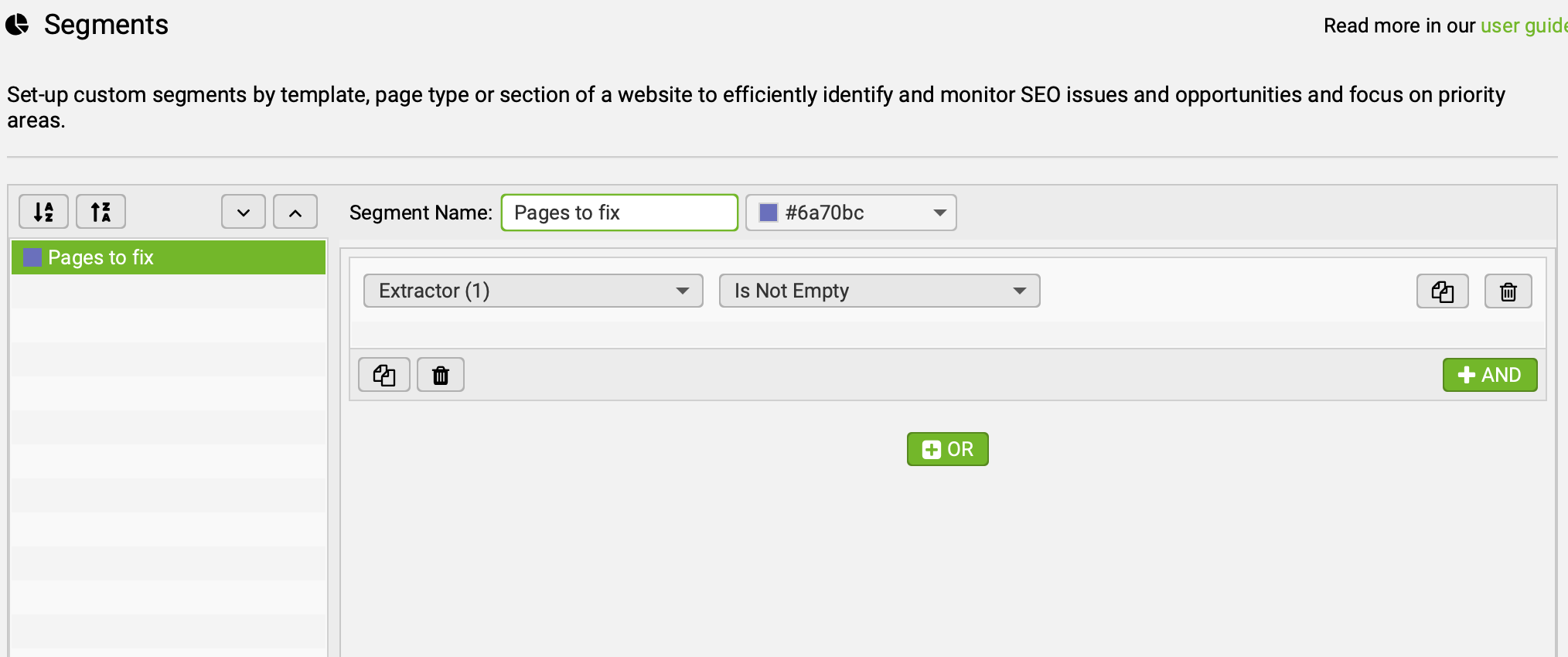
2ème étape : créer un segment
Ensuite, direction les segments.
On va créer un segment permettant d'isoler les pages contenant des liens avec un ID affilié manquant.
Tout est prêt. On peut lancer le crawl.
3ème étape : lancer les vérifications après le crawl
Une fois le crawl terminé, il faut vérifier 3 choses :
- les pages contenant des liens malformés dans le segment créé précédemment (onglet Custom Extraction)
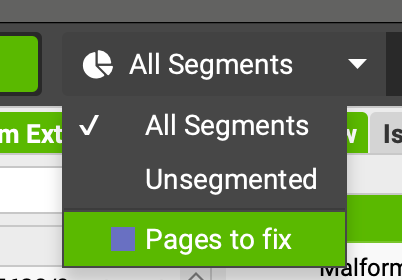
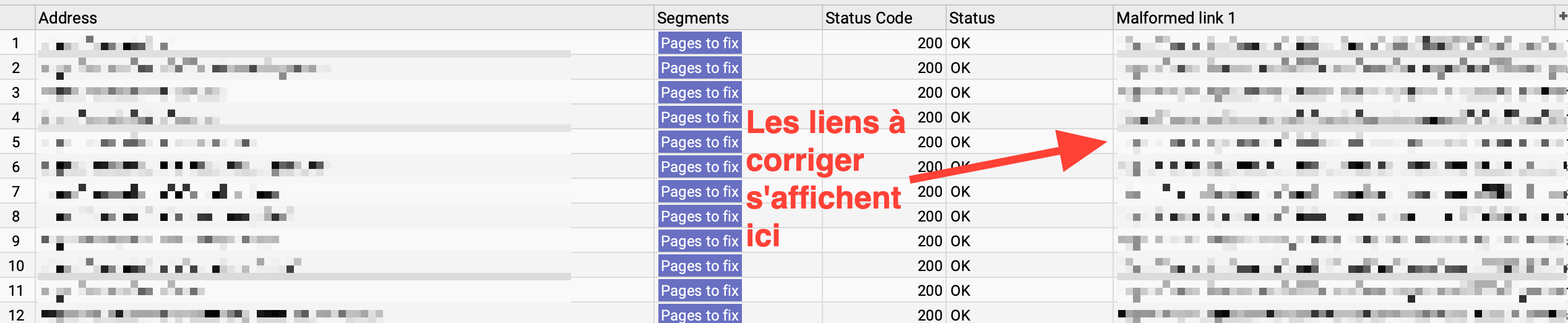
Affichage du segment
- les liens externes en 404 vers le site affilié (filtrer sur le nom de domaine du site affilié)

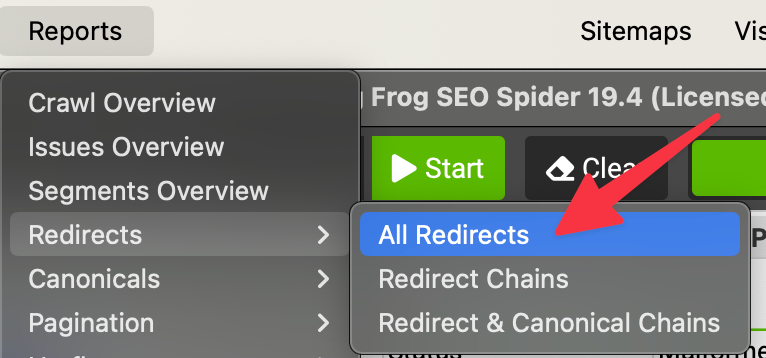
- les liens externes en 301 dont l'URL finale répond en 404 et/ou est malformée ; il faudra ici exporter le fichier des redirections dans Reports > Redirects > All Redirects, puis filtrer les liens affiliés et vérifier que l'URL finale :
- contient bien l'ID de tracking
- n'affiche pas un status code 404 ou autre code d'erreur
Je te conseille de faire ce travail a minima une fois par mois sur ton/tes sites les plus performants pour éviter de perdre "bêtement" des revenus. 🙃
Dernière chose : je n'ai pas traité le cas particulier des liens obfusqués ou cloakés, car il est difficile de donner une solution qui "marche à tous les coups".
Voilà. Bonne journée !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.



{kind=link}