Comment récupérer les URLs d'un sitemap XML avec Screaming Frog (sans les crawler) ?

Table des matières
Il y a quelques semaines, j'ai découvert dans cet article une astuce toute bête mais très pratique pour extraire les URLs d'un sitemap XML avec Screaming Frog.
L'idée c'est d'utiliser le mode liste de Screaming Frog de la façon suivante :
- cliquer sur Download XML Sitemap
- coller l'URL du sitemap
- lancer le crawl
- mettre immédiatement le crawl en pause
- exporter les URLs (Bulk Export > Queued URLs)
Ce qui est cool, c'est que ça fonctionne même avec les index de sitemaps : on récupère directement les URLs listées dans chaque sitemap enfant !
Quand j'ai vu ce hack, je me suis dit qu'on pouvait faire encore plus simple.
En fait, dès que Screaming Frog a terminé de lire toutes les URLs, il suffit de copier toutes les données à partir du 1er "Found" jusque "Completed Reading".
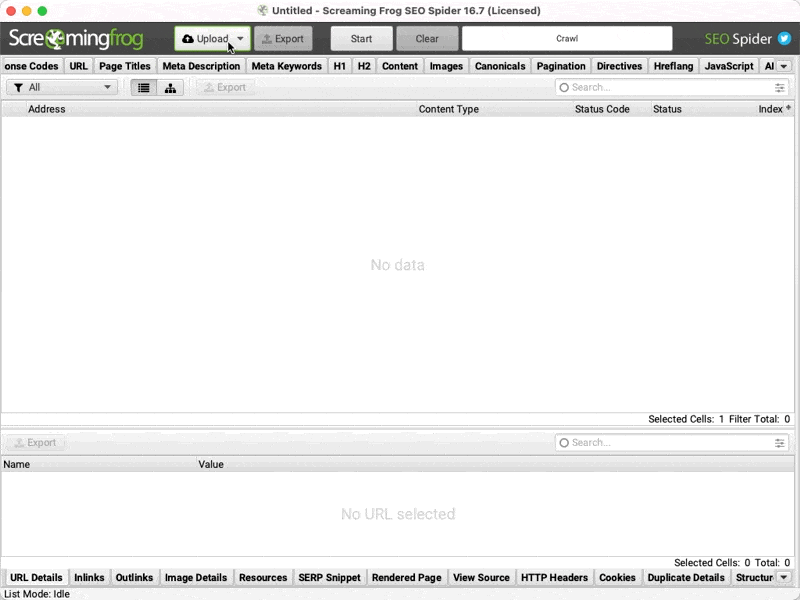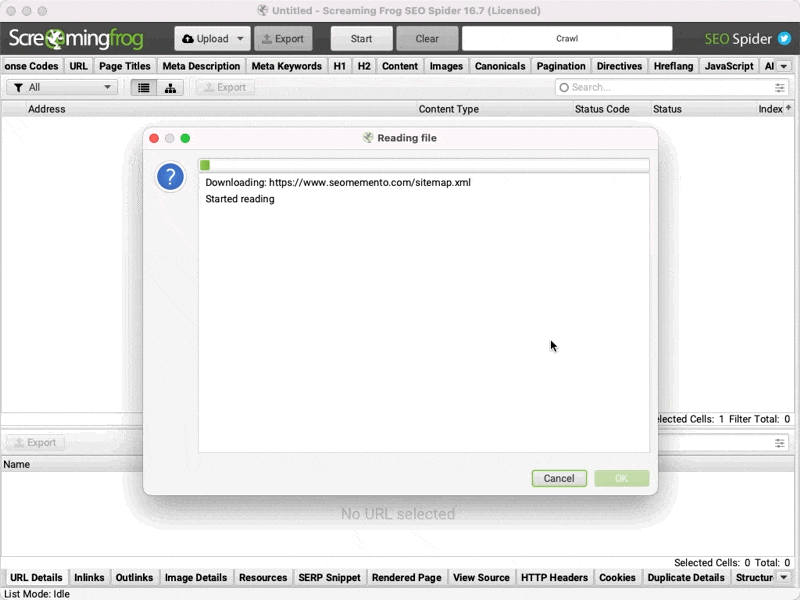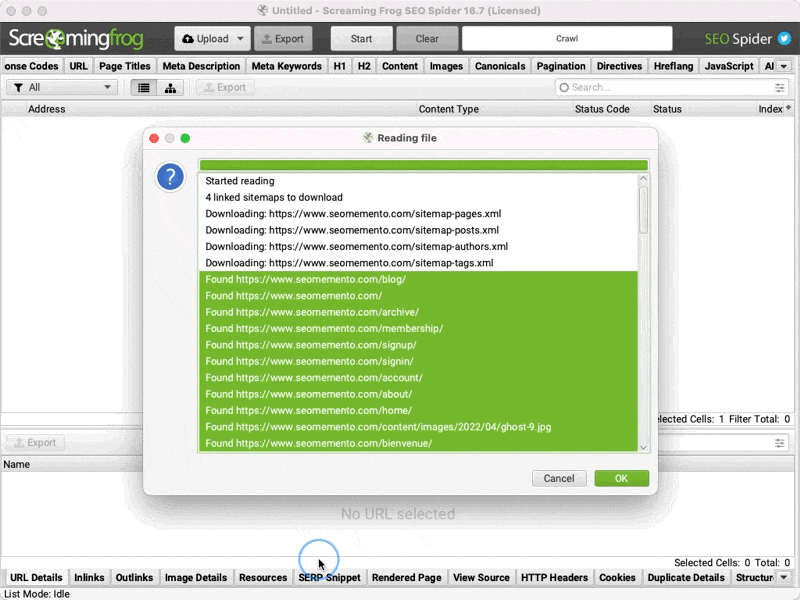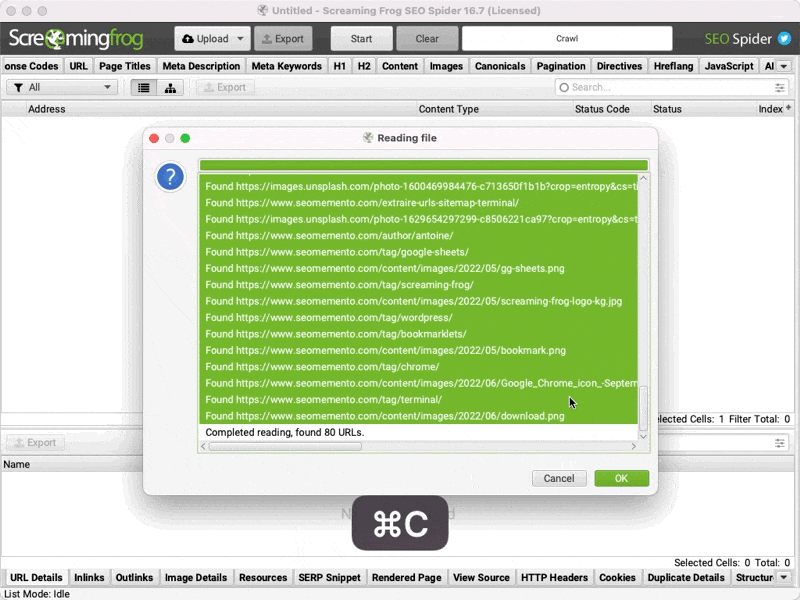
Puis d'ouvrir une feuille de calcul Google Sheets (https://sheets.new/), de coller les données et de cliquer sur Données > Scinder le texte en colonnes.

Et voilà !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.