Comment vérifier la hiérarchie des balises h1 à h6 avec Screaming Frog ?

Table des matières
Est-ce que tu t'es déjà demandé comment faire pour identifier facilement les pages d'un site où la hiérarchie des balises h1, h2, h3, h4, h5 et h6 n'est pas respectée ?
Si la réponse à cette question est oui, l'astuce du jour va te plaire.
Petit rappel
Pour rappel, la bonne pratique consiste à imbriquer correctement les balises Hn : le h2 dépend hiérarchiquement du h1, le h3 dépend hiérarchiquement du h2, etc.
En gros, ça c'est OK ✅
– h1
– – h2
– – h2
– – – h3
– – – h4
Mais ça non ❌
– – h2
– – – – – h5
– – – – – – h6
Pourquoi ?
Parce que sur ce 2ème exemple il manque à la fois un h3 et un h4 avant le h5.
Bref, tu as saisi l'idée. Revenons-en à nos moutons.
Les outils existants
Pour vérifier la cohérence de ces titres "à la main", page par page, il existe deux solutions assez pratiques :
- le plugin HeadingsMap
- le plugin Web Developer Toolbar (Information > View Document Outline)
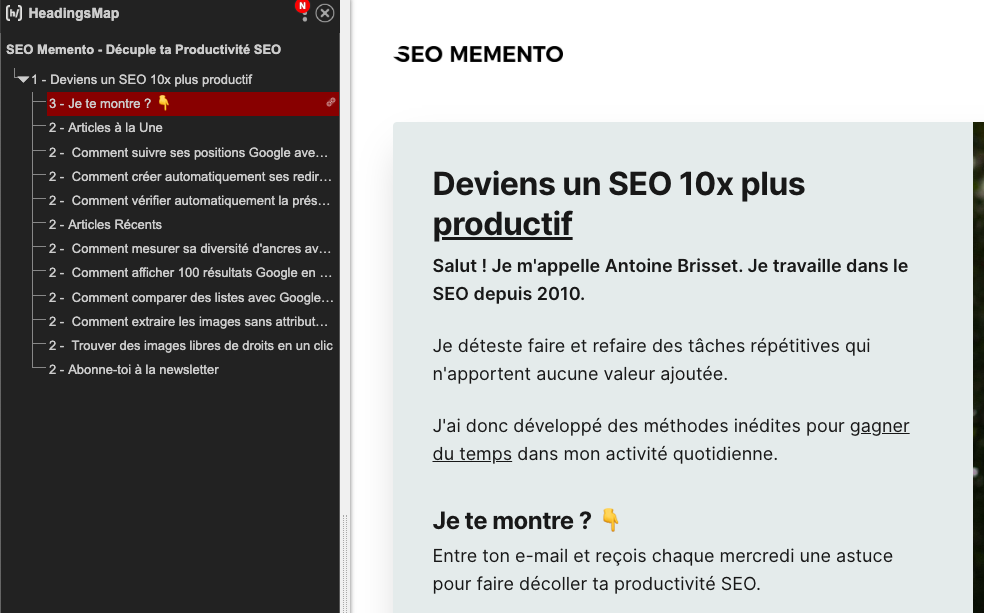
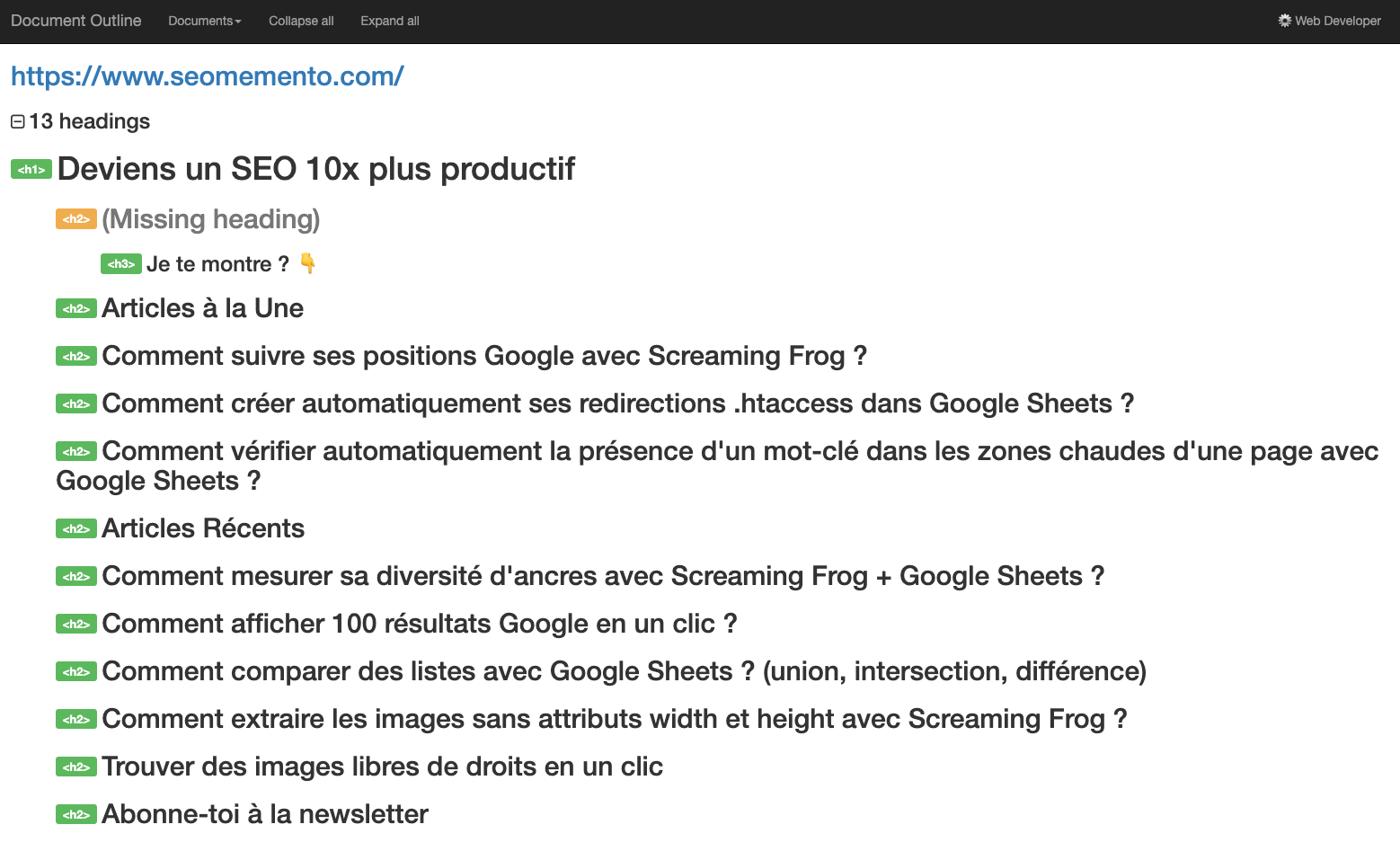
En revanche, dès qu'il s'agit d'automatiser l'analyse, de le faire en masse, c'est beaucoup plus compliqué.
À ma connaissance, aucun logiciel ne propose cette fonctionnalité.
Je me suis donc retroussé les manches et j'ai trouvé la solution... avec Screaming Frog.
La solution en mode bulk avec Screaming Frog
Ce n'est plus un secret, tu sais que j'adore cet outil et en particulier sa feature "custom extraction".
C'est précisément celle-ci que je vais utiliser.
L'objectif, c'est de trouver l'expression XPath permettant de récupérer les Hn qui sont au mauvais endroit dans le code HTML.
Trouver les h1 et h2 mal positionnés
Pour le h1, c'est assez simple, il suffit de vérifier s'il est précédé d'une balise Hn, quelle qu'elle soit.
La requête XPath est la suivante :
//h1[preceding::h2 or preceding::h3 or preceding::h4 or preceding::h5 or preceding::h6]Explications :
//h1: je cherche tous les h1[preceding::h2]: précédés dans le document d'un ou plusieurs h2or preceding::h3 or preceding::h4 or preceding::h5 or preceding::h6: ou précédés d'un ou plusieurs h3, h4, h5 ou h6
Et pour le h2, c'est la même idée, il suffit d'isoler les balises qui ne sont pas précédées d'un h1.
//h2[not(preceding::h1)]Plus d'infos sur not ici et sur preceding ici.
Trouver les h3 à h6 mal positionnés
Naïvement, je me suis dit que je pouvais utiliser la même requête pour toutes les autres balises, de h3 à h6.
Par exemple, pour les h3 :
//h3[not(preceding::h2)]Sauf qu'en réalité, c'est un poil plus complexe.
Prenons un 1er exemple.
– h1
– h1
– – – h3
Dans le cas ci-dessus, ça fonctionne, le XPath cible bien le h3 qui pose problème ✅
OK. Passons au 2ème exemple.
– – h2
– – h2
– h1
– – – h3
Ici, ça ne fonctionne pas ❌
Pourquoi ? On a pourtant un h3 qui suit immédiatement un h1, non ?
Oui. Mais comme avant le h1, on trouve un h2 (en gras dans l'exemple), le h3 en erreur n'est pas comptabilisé.
Conclusion : l'expression //h3[not(preceding::h2)] produit des faux négatifs.
Pour corriger cela, il faut donc ajouter un niveau de vérification supplémentaire, en s'assurant que le h3 qui arrive après le h1 n'est pas précédé d'un h2 ayant lui-même un h1 après lui.
(Désolé pour le mal de tête.)
Et donc, ça se traduit comment en XPath ?
//h1/following::h3[not(preceding::h2[count(./following::h1)=0])]Explications :
//h1/following::h3: je cherche les h3 situés après le(s) h1 dans le DOM[not(preceding::h2[count(./following::h1)=0])]: ces h3 ne doivent pas être précédés d'un h2 n'ayant aucun h1 situé après lui
Si on veut être complet dans l'analyse des h3 en erreur, il faudra donc "chaîner" les expressions à l'aide d'un pipe (|) :
//h3[not(preceding::h2)]|//h1/following::h3[not(preceding::h2[count(./following::h1)=0])]Bien entendu, plus on descend dans la hiérarchie, plus le nombre de vérifications va augmenter.
Prenons un nouvel exemple avec les h4 pour illustrer.
– – h2
– – – h3
– h2
– – – – h4
– – h2
– – – – h4
Si j'utilise uniquement l'expression //h4[not(preceding::h3)]|//h1/following::h4[not(preceding::h3[count(./following::h1)=0])] , c'est insuffisant.
Pourquoi ?
Parce qu'il n'y a pas de h1 dans la page. Du coup, les 2 balises h4 qui posent problème ne sont pas ciblées par mon XPath.
Il faut donc prévoir ce cas particulier supplémentaire avec //h2/following::h4[not(preceding::h3[count(./following::h2)=0])].
Récapitulatif
Allez, pour t'aider, un petit récap'.
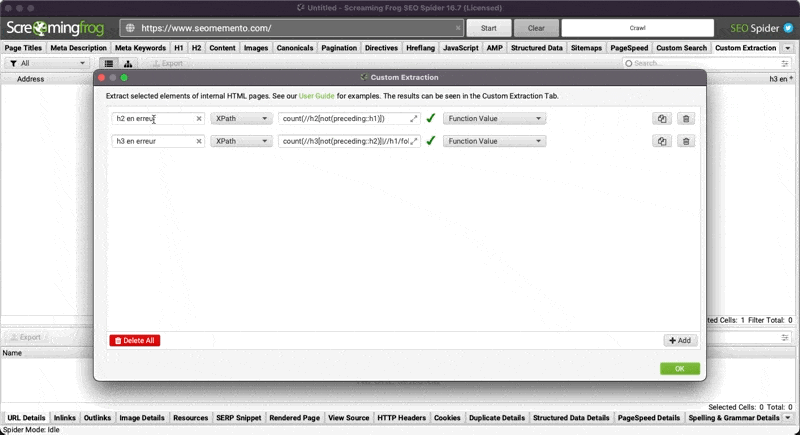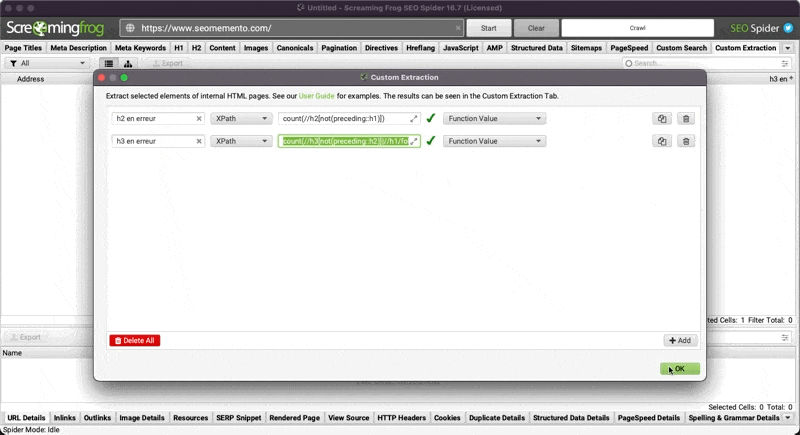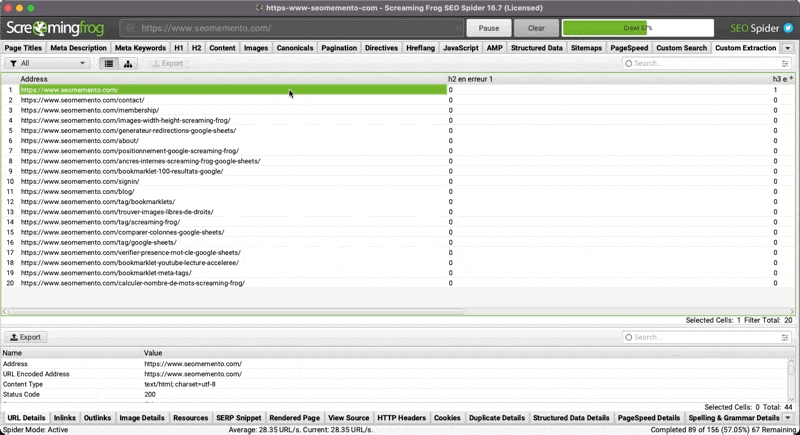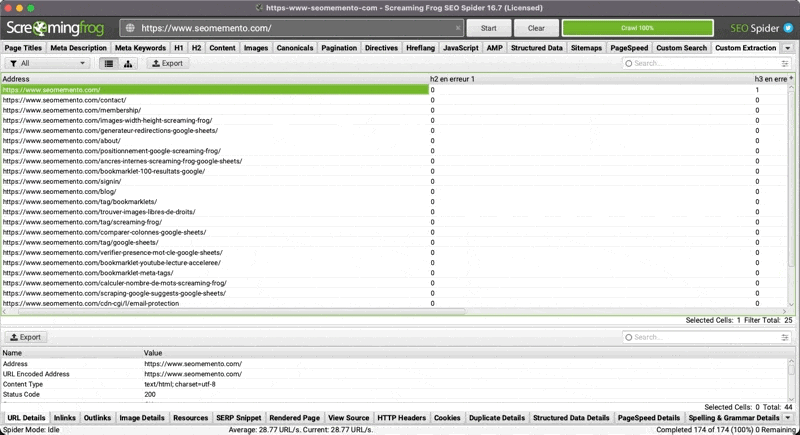
h1 en erreur
//h1[preceding::h2 or preceding::h3 or preceding::h4 or preceding::h5 or preceding::h6]h2 en erreur
//h2[not(preceding::h1)]h3 en erreur
//h3[not(preceding::h2)]|//h1/following::h3[not(preceding::h2[count(./following::h1)=0])]h4 en erreur
//h4[not(preceding::h3)]|//h1/following::h4[not(preceding::h3[count(./following::h1)=0])]|//h2/following::h4[not(preceding::h3[count(./following::h2)=0])]h5 en erreur
//h5[not(preceding::h4)]|//h1/following::h5[not(preceding::h4[count(./following::h1)=0])]|//h2/following::h5[not(preceding::h4[count(./following::h2)=0])]|//h3/following::h5[not(preceding::h4[count(./following::h3)=0])]h6 en erreur
//h6[not(preceding::h5)]|//h1/following::h6[not(preceding::h5[count(./following::h1)=0])]|//h2/following::h6[not(preceding::h5[count(./following::h2)=0])]|//h3/following::h6[not(preceding::h5[count(./following::h3)=0])]|//h4/following::h6[not(preceding::h5[count(./following::h4)=0])]Une précision pour terminer.
Dans Screaming Frog, tu peux, au choix :
- utiliser chaque XPath tel quel : tu retrouveras donc dans ton onglet Custom Extraction le contenu textuel de chacune des balises mal hiérarchisées
- compter les balises en erreur avec la fonction
count, par exemple pour les h3 ça donnerait :count(//h3[not(preceding::h2)]|//h1/following::h3[not(preceding::h2[count(./following::h1)=0])]) - tester si oui ou non des balises sont en erreur avec la fonction
boolean, par exemple pour les h3 ça donnerait :boolean(//h3[not(preceding::h2)]|//h1/following::h3[not(preceding::h2[count(./following::h1)=0])])
Et voilà, y'a plus qu'à !
- Partager sur Twitter
- Partager sur Facebook
- Partager sur LinkedIn
- Partager sur Pinterest
- Partager par E-mail
- Copier le lien

Un Template Google Sheets Offert ! 🎁
Rejoins ma newsletter et reçois une astuce SEO chaque mercredi ! En cadeau, je t'offre un template Google Sheets avec 50 fonctions de scraping prêtes à l'emploi.